Using Flume to transfer data from Kafka to HDFS in Ambari(2.4.2) with Kerberos
Posted onInBack-end
,
BigDataViews: Symbols count in article: 2.5kReading time ≈2 mins.
Firstly, you don’t need to read the following post if your Flume upper than 1.5.2. You can complete your configuration file by following official documents.**
Versions of components
Ambari: 2.4.2
HDP: 2.4.3
HDFS: 2.7.1.2.4
Kafka: 0.9.0.2.4
Flume: 1.5.2.2.4
Unpredictable problem
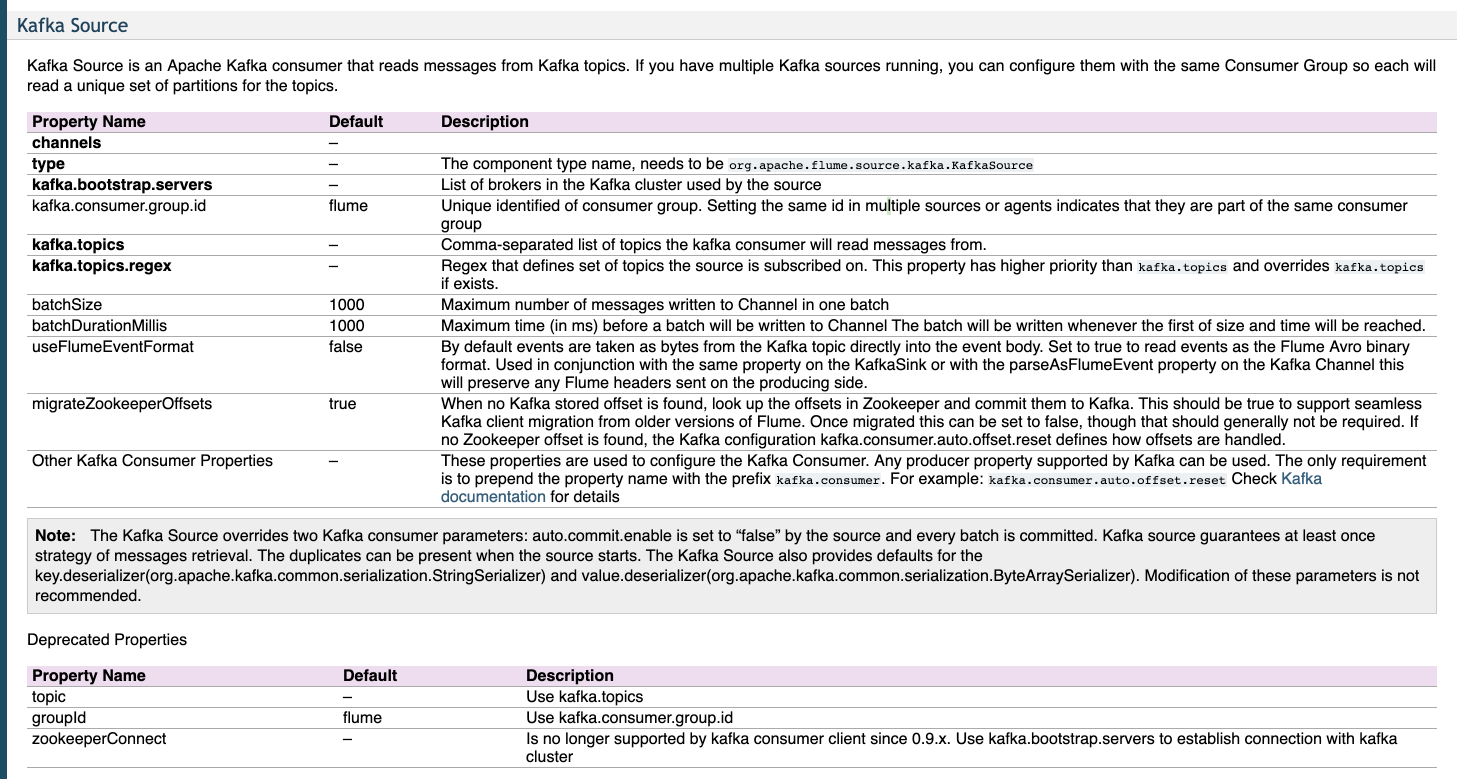
Assume that using Kafka to receive data from a topic, then store data to HDFS. It is obviously a good choice using Kafka source, memory channel, and HDFS sink. Nevertheless, it’s not easy like that after searching User Guide(1.5.2).
After reading the contents above, it is pitiful that Kafka source not supporting Kerberos environment because of no properties for specifying principle and keytab file path. So why Flume 1.5.2 not supporting Kafka source? OK. Let’s check out the library within Flume (/user/hdp/2.4.3.0-227/flume/lib). There are some libs specifying Kafka(0.8.2).
Well, it’s so weird that Ambari-2.4.2 using Kafka-0.9.0, but Flume-1.5.2 in Ambari-2.4.2 not using Kafka-0.9.0 instead of using Kafka-0.8.2. I don’t know why, but I also found similary problem after googling. Kafka starts to support Kerberos authorization after version 0.9. So it’s obvious that we can’t use Kafka source in Flume in Ambari-2.4.2 with Kerberos.
From this moment, we got stuck by this annoying version of conflict. After complaining, we also need to solve this problem. But, how? Although Kafka-0.8.2 not supporting Kerberos, it ought to create a custom Kafka source. Appending Kerberos authorization code within your custom Kafka source that is a reasonable solution for this situation.
Reasonable solution
Creating custom Kafka(0.9.0) source
Writing your custom Kafka source which inheriting class AbstractSource is just like a Kafka consumer.
Attention: The dependencies of Kafka need to use the version of 0.9.0.
Using the code “context.getString()” can get specific property value from your configuration file.
Generating jar package
Utilizing your build automation tool - such as Maven, Gradle and etc - to generate your custom Kafka source jar.
Replacing Kafka lib and Adding custom Kafka source jar
In this step, you ought to download a Kafka jar package (the version is 0.9.0), then copy the file “kafka-clients-0.9.0.0.jar” and the file that custom Kafka source jar to your lib path of Flume(/usr/hdp/2.4.3.0-227/flume/lib). After that, you also need to delete the old version of Kafka client jar(kafka-clients-0.8.2.0.jar).
Other preparation for the final point
Creating a Kafka topic and ensuring that it’s working.