Using Flume in Ambari with Kerberos

What is Flume
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
An Event is a unit of data, and events that carrying payloads flows from source to channel to sink. All above running in a flume agent that runs in a JVM.
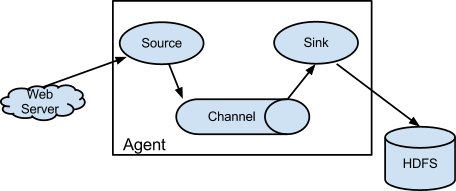
Three key components of Flume:
- Source
The purpose of a source is to receive data from an external client and store it in a configured channel.
- Channel
The channel is just like a bridge which receives data from a source and buffers them till they are consumed by sinks.
- Sink
Sinks can consume data from a channel and deliver it to another destination. The destination of the sink might be another agent or storage.
Attention:
In HDP3.0, Ambari doesn’t use Flume continuously instead of using Nifi.
Kerberos authorization
Before we use flume, we need to configure it in Ambari with Kerberos. Visit Ambari UI and click the “Flume” service to change the configuration file.
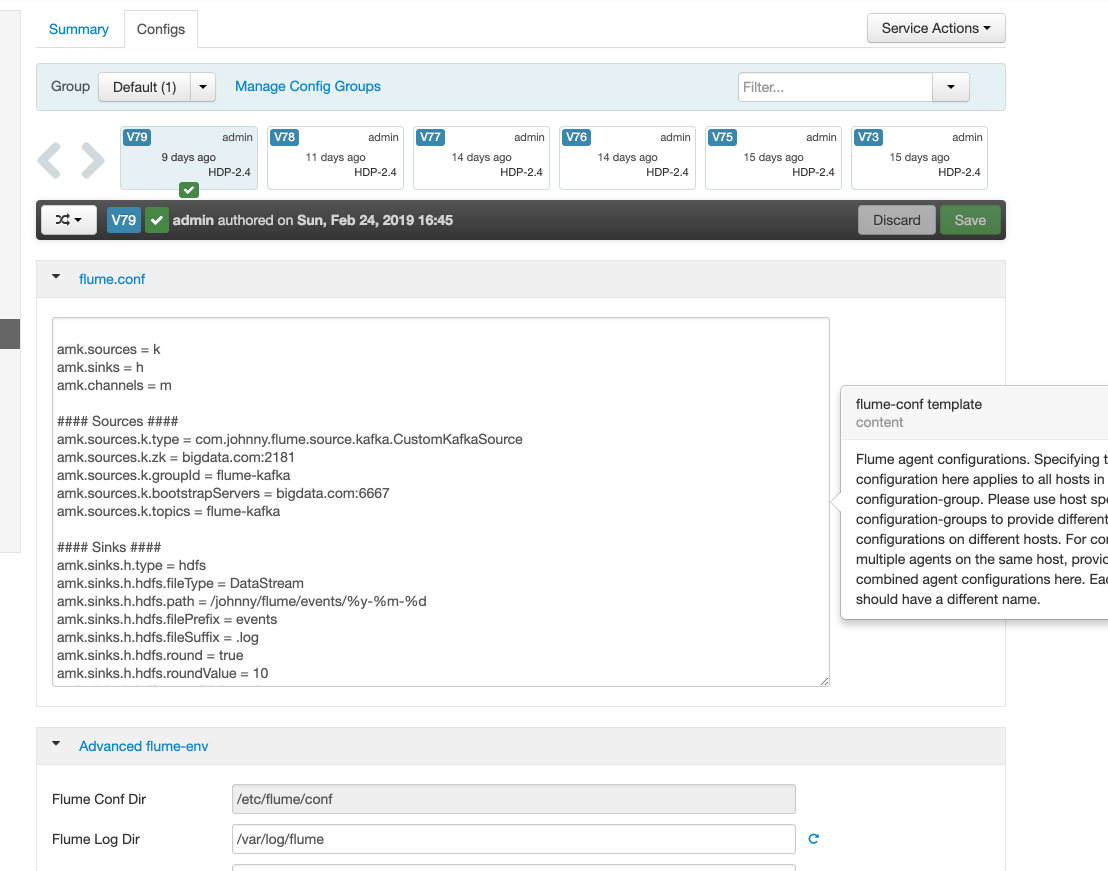
More importantly, you need to append security content at the end of the property “flume-env template” when you using Kafka components with Kerberos. Every Kafka client needs a JAAS file to get a TGT from TGS.
1 | export JAVA_OPTS="$JAVA_OPTS -Djava.security.auth.login.config=/home/flume/kafka-jaas.conf" |
Configuration
There is a simple example that transferring log data from one pc to another pc, and I paste the configuration code below.
Using avro-source and avro-sink is a perfect choice to transfer data from one agent to another agent.
One PC configuration
source: exec-source
channel: memory
sink: avro-sink
1 | exec-memory-avro.sources = exec-source |
Another PC configuration
source: avro-source
channel: memory
sink: logger
1 | avro-memory-logger.sources = avro-source |