Cheat Sheet for AWS SAA-02

IAM
- IAM role policy only define which API actions can be made to that role.
VPC
each account can create 5 VPC, and each vpc can create 200 subnets
private subnet => NAT Gateway => IGW
Direct Connect can provide 1Gbps to 10Gbps private network, but not encryption.
For accessing applications in different regions privately, you can configure inter-region VPC peering and create a VPC endpoint for specific service or application
NACLs & SG
- By default, new created SG only allow all connection from the outbound. New created NACLs deny both inbound and outbound connection
- However, default NACLs is configured to allow all traffic to flow in and out of the subnets to which it is associated.
- NACLs
- The lower number rule has precedence
- If a request comes into a web server in your VPC from a computer on the internet, your network ACL must have an outbound rule to enable traffic destined for ports 49152-65535 (ephemeral ports)
- SGs
- Inbound Rules: by default, disallow all traffic
- Outbound Rules: by default, allow all traffic
VPC Endpoint
- VPC Endpoint Policy
- VPC has a policy which by default allows all actions on all S3 buckets. We can restrict access to certainn S3 buckets and certain actions on this policy. In such cases, for accessing any new buckets or for any new actions, the VPC endpoint policy needs to be modified accordingly.
- VPC Endpoints does not supported outside VPC
- Two types
- Interface Endpoint
- is an elastic network interface (ENI) with a private IP address
- Gateway Endpoint
- Currently supports S3 and DynamoDB
- Interface Endpoint
- VPC Endpoint Policy
VPN
- Site-to-Site VPN provide encryption connection through Internet, not private network.
- Policy-based VPNs using one or more pairs of security associations drop already existing connections when new connection requests are generated with different security associations. This cause intermittent packet loss and other connectivity failures.
- Using Route-Based VPNs can get rid of connectivity issues of Policy-Based VPNs
- CloudHub
- To use AWS VPN CloudHub, one must create a Virtual Private Gateway with multiple Customer Gateways, each with a unique Border Gateway Protocol (BGP) Autonomous System Number (ASN)
- VPN CloudHub operates on a simple hub-and-spoke model that you can use with or without a VPC. This design is good for primary or backup connectivity between remote offices.
- The sites must not have overlapping IP ranges
- Each Customer Gateway must attach a public IP address. You must use a unique Border Gateway Protocol (BGP) Autonomous System Number (ASN) for each Customer Gateway.
- VGW by default acts as a Hub and spoke & no additional configuration needs to be done at the VGW end.
- Each router in each spoke needs to have BGP peering only with VGW & not with routers in other locations.
- This design is suitable if you have multiple branch offices and existing internet connections and would like to implement a convinient, potentially low-cost hub-and-spoke model for primary or backup connectivity between these remote offices
- Process for creating Site-to-Site VPN
- Specify the type of routing that you plan to use (static or dynamic)
- Update the route table for your subnet
- Static and Dynamic Routing
- the type of routing that you select can depend on the make and model of your customer gateway device.
- If your customer gateway device support Border Gateway Protocol (BGP), specify dynamic routing. If not, specify static.
- Reducing backup time of large data size by using VPN
- Enable ECMP on on-premises devices to forward traffic on both VPN endpoints
- ECMP (Equal Cost Multi-Path) can be used to carry traffic on both VPN endpoints, increasing performance and faster data transfer.
- ECMP needs to be enabled on Client end devices and not on the VGW end.
- Customization
- AWS Site-to-Site VPN offers cutomizable tunnel options including inside tunnel IP address, pre-shared key, and Border Gateway Protocol Autonomous System Number (BGP ASN). In this way, you can set up multiple secure VPN tunnels to increase the bandwidth for your applications or for resiliency in case of a down time. In addition, equal-cost multi-path routing (ECMP) is available with AWS Site-to-Site VPN on AWS Transit Gateway to help increase the traffic bandwidth over multiple paths.
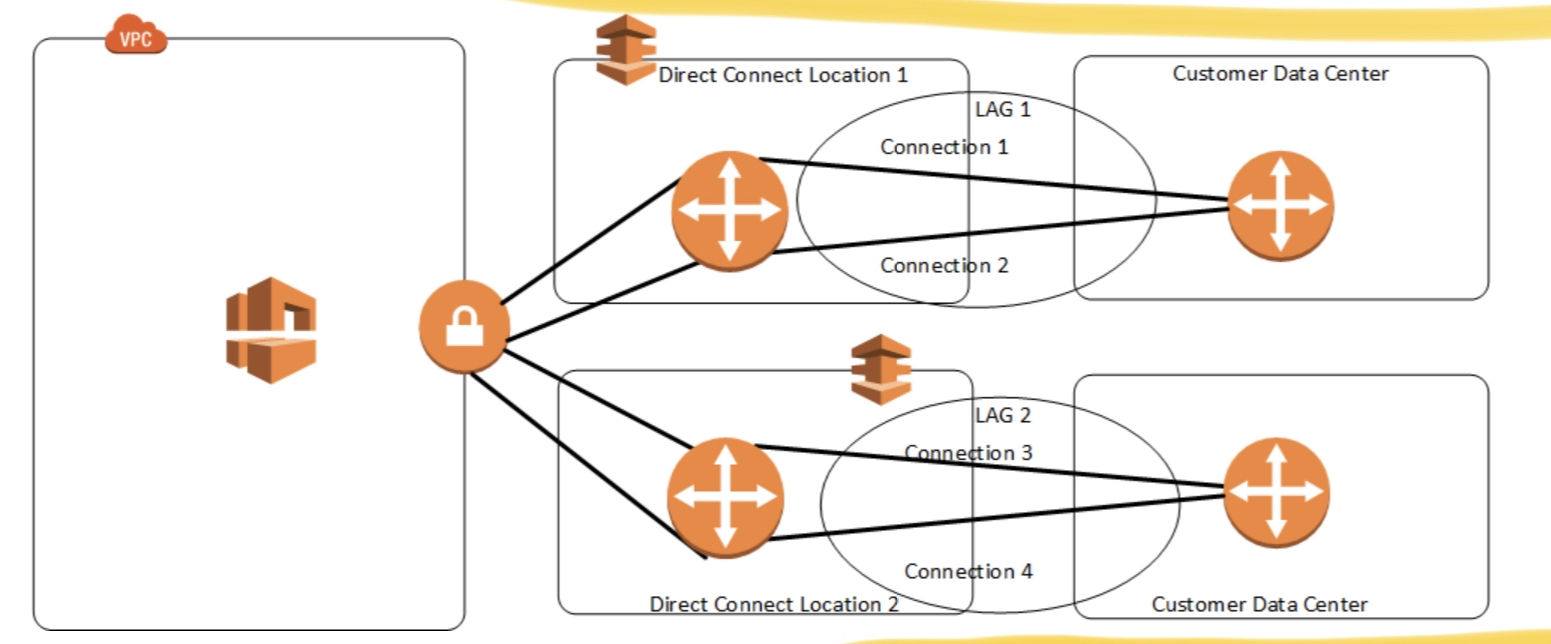
LAGs
- LAG stands for Link Aggregation Groups
- You can use multiple connections for redundancy.
- A LAG is a logical interface that uses the Link Aggregation Control Protocol (LACP) to aggregate multiple connections at a single AWS Direct Connect endpoint, allowing you to treat them as a single, managed connection.

- For higher throughput, LAG can aggregate multiple DX connections to give a maximum of 50 Gig bandwidth.
A NAT Gateway cannot send traffic over VPC endpoints, VPN connections, AWS Direct Connect, or VPC Peering connections.
You can associate secondary IPv4 CIDR blocks with your VPC. When you associate a CIDR block with your VPC, a route is automatically added to your VPC route tables to enable routing within the VPC (the destination is the CIDR block ad the target is local).
A subnet’s CIDR cannot be edited once created
Route Tables Target Naming
- VPC Peering: pcx-xxxx
- VPN: vgw-xxxx
- Direct Connect: vgw-xxxx
VPC Peering
- For the private connections between regions, VPC peering should be used. Then VPC endpoint allows users to access the DynamoDB service privately.
- doesn’t support transitive routing
Visting websites that belongs to the same region, the latency will be almost same.
Transit Gateway
- AWS Transit Gateway centralize outbound internet traffic from multiple VPCs using hub-and-spoke design.
Hybrid Option: Direct Connect + VPN
- VPN is needed as it creats an IPsec connection. Direct Connect is also required because it establishes a private connection with high bandwidth throughput.
- With Direct Connect + VPN, you can create IPsec-encrypted private connection.
For resources can be accessed from Internet
Need an IGW
The route table needs to be attched to an IGW that is created for the VPC
EC2
- Instance Type
- R: more ram
- C: more CPU
- M: balanced type
- I: more I/O
- G: more GPU
- Instance type offers different compute, memory, and storage capabilities, and is grouped in an instance family based on these capabilities.
- Launch Mode
- On-Demand
- Spot Instance
- Reserved
- Dedicated
- Placement Group
- Types
- Cluster (better for HPC)
- instances are all in one AZ
- cluster cannot be multi-AZ
- cluster is not available in t2.micro
- for HPC
- all the instances are placed in the same rack in the same AZ
- Spread (better for resolving simultaneous failures)
- can be multi-AZ
- cannot span across multiple regions
- supports a maximum of 7 running instances per AZ
- appropriate for availability scenarios
- the insatnces in different racks. Every rack has its own hardware and power source.
- Partition (better for Big Data)
- within one AZ
- each partition do not share the underlying hardware with each other
- Cluster (better for HPC)
- Placement Group supports migrating instances between palcement groups, but not merging them
- Placement Group cannot span multiple regions
- Types
- EC2 Hibernate
- Pre-warm EC2 instance
- The instance needs to be launched with an EBS root volume
- Note: You cannot hibernate an instance in an ASG or used by ECS
- The instance retains its private IPv4 addresses and any IPv6 addresses when hibernated and started.
- When an EC2 instance is in the Hibernate state, you pay only for the EBS volumes and Elastic IP addresses attached to it.
- Metadata
ASG
ASG launches new instances based on the configuration defined in Launch Configuration
AMI ID is set during the creation of launch configuration and cannot be modified.
Using Auto Scaling is good for
- Better fault tolerance
- Better availability
Default metric type for Simple Policy
- ALB Request Count Per Target
- Average Network In
- Average Network Out
Memory Utilization
Default metric type for Step Policy
- CPU Utilization
- Disk Reads
- Disk Read Operations
- Disk Writes
- Disk Write Operations
- Network In
- Network Out
ASG Scaling Policies
- Target Tracking Scaling Policy
- Maintains a specific metric at a target value
- ex: want average CPU to stay at 40%
- Simple Scaling Policy (based on a single adjustment)
- Scales when an alarm is breached
- ex: when a CloudWatch alarm is triggered (CPU > 70%), then add 2 units
- Scaling Policies with Steps (based on step adjustments)
- Scales when an alarm is breached, can escalates based on alarm value changing
- Main difference between Simple Scaling Policy and Step Simple Scaling Policy is the step adjustments
- The adjustments vary based on the size of the alarm breach
- ASG react to the lower and upper bound metrics value
- AWS recommends Step Scaling Policies as a better choice than simple scaling polices.
- Scheduled Actions
- Target Tracking Scaling Policy
You can have multiple scaling policies in force at the same time
ex: multiple target tracking scaling policies for an ASG, provided that each of them uses a different metric.
If two policies are executed at the same time, EC2 Auto Scaling follows the policy with the greater impact. For example, if you have one policy to add two instances and another policy to add four instances, EC2 Auto Scaling adds four instances when both policies are triggered simultaneously.
Termination Policy
- OldestInstance
- Terminate the oldest instance in the group
- NewestInstance
- Terminate the newest instance in the group
- OldestLaunchConfiguration
- Terminate instances that have the oldest launch configuration
- ClosestToNextInstanceHour
- Terminate instances that are closest to the next billing hour
- Default
- Find the AZ which has the most number of instances
- If there are multiple instances in the AZ, delete the one with the oldest launch configuration
- If there are multiple instances, choose the instance which are closest to the next billing hour
- If there are multiple instances, select one of them at random
- OldestInstance
ASG tries the balance thee number of instances across AZ by default
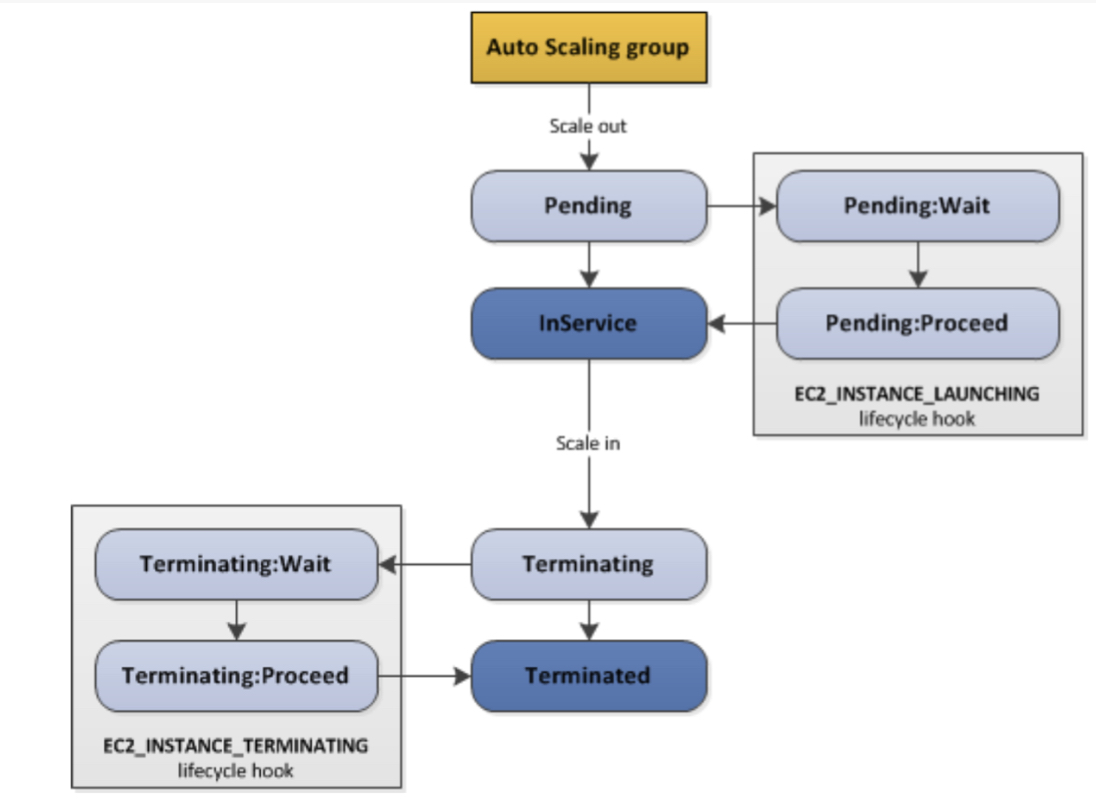
Lifecycle Hooks
- By default as soon as an instance is lanched in an ASG it’s in service
- You have the ability to perform extra steps before the instance goes in service (Pending State)
- You have the ability to perform some actions before the instance is terminated (Terminating State)
Salcing Cooldown
- Cooldown period helps to ensure that your ASG doesn’t luanch or terminate additional instances before the previous scaling activity takes effect
- We can create cooldowns that apply to a specific scaling policy
IAM roles attached to an ASG will get assigned to EC2 instances
ASG is free, but the underlying resources are not free
better scaling rules that are directly managed by EC2
- Target Average CPU Usage
- Number of requests on the ELB per instance
- Average Network In
- Average Network Out
By default, Amazon EC2 Auto Scaling health checks use the results of the EC2 status checks to determine the health status of an instance
Health Check Grace Period
- AS instance that has just come into service needs to warm up before it can pass the health check.
- EC2 AG waits until the health check grace period ends before checking the health status of the instance
ASG supports a mix of On-Demand & Spot instances, which helps design a cost-optimized solution without impacting the performance. You can choose the percentage of On-Demand & Spot instances based on the application requirement (OnDemandPercentageAboveBaseCapacity)
EBS
- Storage Type
- gp2:
- general purpose, max 16,000 IOPS, max 250 MB/s throughput
- IOPS is increased with volume size
- io1:
- high IOPS, max 64,000 IOPS, max 1,000 MB/s throughput
- IOPS is not increased with volume size
- st1:
- high throughput, HDD, max 500 IOPSmax 500MB/s throughput
- sc1:
- lowest price, HDD, max 250 IOPS, max250MB/s throughput
- gp2:
- EBS Snapshot Lifecycle
- You cann use Amazon Data Lifecycle Management (DLM) to automate the creation, retention, and deletion of snapshots taken to back up your EBS volumes.
- Automating snapshot management helps you to
- Protect valuable data by enforcing a regular backup schedule
- Retain backups as required by auditors or internal compliance
- Reduce storage costs by deleting outdated backups
- You can back up the data on your EBS volumes to S3 by taking point-in-time snapshots. Snapshots are incremental backups, which means that only the blocks on the device that have changed after you most recent snapshot are saved. This minimizes the time required to create the snapshot and saves on storage costs by not duplicating data. When you delete a snapshot, only the data unique to that snapshot is removed. Each snapshot contains all of the information needed to restore your data (from the moment when the snapshot was taken) to a new EBS volume.
- EBS Performance Tips
- EBS-optimized instance
- EBS-optimized instance uses an optimized configuration stack and provides additional, dedicated capacity for EBS I/O. This optimization will minimize contention between EBS I/O and other traffic from your instance.
- Use a Modern Linux Kernel
- Use RAID 0 to Maximize Utilizationn of Instance Resource
- You can join multiple gp2, io1, st1, or sc1 volumes together in a RAID 0 configuration to use available bandwidth for these instances.
- EBS-optimized instance
- EBS Encryption
- Ensuring the security of both data-at-rest and data-in-transit between an instance and its attached EBS storage.
- You can enable encryption while copying a snapshot from an unencrypted snapshot
- You cannot remove encryption from an encrypted snapshot
- You cannot create an encrypted snapshot from an uncrypted volume
- CloudWatch Metrics for EBS
- VolumeReadBytes / VolumeWriteBytes
- VolumeReadOps / VolumeWriteOps
- VolumeTotalReadTime / VolumeTotalWriteTime
- VolumeIdleTime
- VolumeQueueLength
- VolumeThroughputPercentage
- VolumeConsumedReadWriteOps
- BurstBalance
VolumeRemainingSize
- EBS Elastic Volumes
- With EBS Elastic Volumes, you can increase the volume size, change the volume type, or adjust the performance of your EBS volumes. If you instance supports Elastic Volumes, you can do so without detaching the volume or restarting the instance.
Instance Store
- Data in the instance store is lost under any of the following circumstances
- The underlying disk drive fails
- The instance stops
- The instance terminates
- Data will not lost during reboot
- You can only specify the size of your instance store when you launch an instance. You can’t change it or attach new after you’ve launched it.
EFS
- EFS works with EC2 instances in multi-AZ
- Uses SG to control access to EFS
- Performance Mode (set at EFS creation time)
- General purpose (default): latency-sensitive use cases (web server, CMS)
- Max I/O - higher latency, throughput, highly parallel (big data, media proessingn)
- The performance mode of an EFS cannot be changed after the file system has been created
- Throughput Mode
- Bursting Throughput: With Bursting Throughput mode, a file system’s throughput scales as the amount of data stored in the EFS standard or one zone storage class grows.
- Provisioned Throughput: Provisioned throughput is available for applications with high throughput to storage
- Storage Class (life cycle management feature - move files after N days)
- Standard: for frequently accessed files
- Infrequent access (EFS-IA): cost to retrieve files, lower price to store
- Can leverage EFS-IA for cost saving
- Note: An EFS file system can only have mount targets in one VPC at a time
- When you use a VPC peering connection or VPC Transit Gateway to connect VPCs, EC2 instances in one VPC can access EFS in another VPC, even if the VPCs belong to different accounts.
- Mount targets can have associated SGs
- And SG on mount targets need inbound rules for allowing TCP 2049 from SG of EC2
- Encryption of data at rest can only be enabled during file system creation
- NFS is nont an encrypted protocol
- When you need encryption in transit, you can use Amazon EFS mount helper during mounting
- Diff between EFS and EBS
- Availability and durability
- EFS
- Data is stored redundantly across multiple AZs
- EBS
- Data is stored redundantly in a single AZ
- EFS
- Acess
- EFS
- thounds of EC2 instances from multi-AZs can connect
- EBS
- single EC2 instance in a single AZ can connect
- EFS
- Use Cases
- EFS
- Big data and analytics, media processing, content management, web serving
- EBS
- Boot volumes, transcational and NoSQL databases, data warehousing, and ETL
- EFS
- Availability and durability
- You can mount EFS over VPC connections by using VPC peering within a single AWS Region, not support inter-region VPC peering.
- Mount Target
- You can create one mount target in each AZ (recommended way)
- If the VPC has multiple subets in an AZ, you can create a mount target in only one of those subnets. All EC2 instances in the AZ can share the single mount target
Serverless
- S3
- Athena
- DynamoDB
- Lambda
- SNS, SQS
- Aurora Serverless
- API Gateway
S3
4 9’s avaialbility, and 11 9’s durability
S3 is a managed service and not part of VPC. So, VPC flow logs does not report traffic sent to the S3 bucket.
Storage Class
- Standard
- Standard-IA
- DR, backup
- access less than a month, additional retrieve fee needs
- One Zone-IA
- only exist in one AZ, additionnal retrieve fee needs
- secondary backups for on-premise data
- Intelligent Tiering
- using ML to analyse your usage and determine the appropriate storage class
- When the access pattern to web application using S3 storage buckets is unpredictable, using intelligent tier.
- Intelligent Tiering storage class includes two access tiers
- frequent access
- infrequent access
- Intelligent Tiering storage class has the same performance as that of Standard storage class
- Glacier
- for long-term cold storage
- Glacier Deep Archive
- the lowest cost storage class.
- Data retrieval time is 12 hours
Strong Consistency
- What you write is what you will read, and the results of a LIST will be an accurate reflection of what’s in the bucket. This applies to all existing and new S3 objects, works in all regions, and is available to
you at no extra charge!
- What you write is what you will read, and the results of a LIST will be an accurate reflection of what’s in the bucket. This applies to all existing and new S3 objects, works in all regions, and is available to
CRR & SRR
- must turn on “versioning” on source and destination bucket
- replication cannot be chaining
- only replicate new objects, do not be retroactive
- CRR can copy encrypted objects across buckets in different regions
- Users can choose one or more KMS keys in the replication rule.
- re-encryption is not required for the CRR
Lifecycle Management
- help to move objects to different storage class or delete objects in time
- Actions for Lifecycle Management
- Transition actions
- Expiration actions
Performance
- if you use KMS, your S3’s performance may impacted by KMS
How to improve performance
- Upload
- Multi-Part Uploads
- S3 Transfer Acceleration (compatible with Multi-Part Upload)
- using edge location to speed up
- Download
- S3 “Byte-Range” HTTP header in a GET request to download the specified range bytes of an object
- Upload
S3 Select & Glacier Select
- Retrieve specific data using SQL by performing server side filtering
- S3 Glacier Select can directly query data from S3 Glacier & restoration of data to the S3 bucket is not required for querying this data.
- For using S3 Select, objects need to be stored in an S3 bucket with CSV, JSON, or Apache Parquet format. GZIP & BZIP2 compression is supported with CSV or JSON format with server-side encryption.
Event Notification
- 3 targets for events: SNS, SQS, Lambda
- If you don’t want miss any notifications, you need to enable versioning
Make a static website
Properties choose “use this bucket to a static website”
Permission “Public Access Settings”
Permission “Bucket Policy”
Bucket Policy
- If a bucket policy contains Effect as Deny. You must whitelist all the IAM resources which need access on the bucket. Otherwise, IAM resources cannot access the S3 bucket even if they have full access.
- Server Access Logging
- Server Access Logging provides detailed records for the requsets that are made to a bucket. Can be useful in security and access audits
- Metadata
- System Metadata
- such as object creation date is system controlled where only S3 can modify the value
- User-Defined Metadata
- When uploading an object, you can also assign metadata to the object. You provide this optional information as a name-value pair when you send PUT or POST request to create the object. When you upload objects using the REST API, the optional user-defined metadata names must begin with “x-amz-meta-“ to distinguish them from other HTTP headers.
- URLs for accessing objects
- Virtual Hosted-Style Requests
- Path-Style Requests
Old version of an existing object is also be charged by AWS.
Types of SSE (at-rest)
- SSE-S3
- SSE-KMS
- SSE-C
S3 bucket owner can create Pre-Signed URLs to upload images to S3
Object ACLs
Object level, not bucket level
Using Object ACLs provides a granular control on each file in S3 bucket
- S3 Select vs Athena
- S3 Select only support simple SELECT statement, no joins or subqueries
- Athena supports full standard SQL
With version enabled S3 buckets, each version of an object can have a different retention period
S3 CORS
- what is different origin
- different doamin or subdomain
- different protocol or different ports
- the limit number of CORS is 100
- The scheme, the hostname, and the port values in the Origin request header must match the AllowedOrigin elements in the CORSRule.
- For example, if you set the CORSRule to allow the origin “http://www.example.com", then both “https://www.example.com" and “http://www.example.com:80" origins in your request don’t match the allowed origin in your configuration. By the way, “www.example.com" and “example.com” are not the same hostname
- CORS configuration can use JSON or XML format.
- CORS only supports GET, PUT, POST, DELETE, and HEAD.
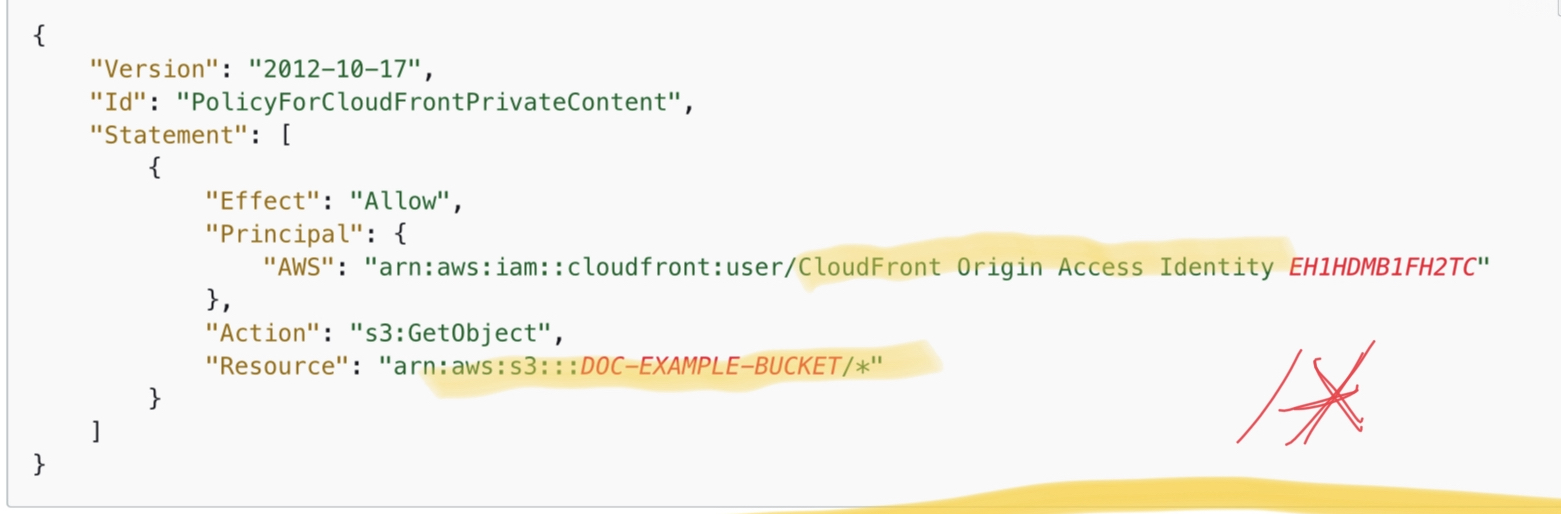
S3 bucket policy should allow the “S3:GetObject” action if the Principal comes from the CloudFront Origin Access Identity.
Bucket Policy for OAI
- Object Lock
- Object Lock should be enabled to store objects using write once and read many (WORM) models.
- You can prevent the S3 objects from being deleted or overwritten for a fixed amount of time or indefinitely.
- Note: Versioning does not prevent objects from being deleted or modified.
- Event Notification
- you can use Event Notification from the S3 bucket to invoke the Lambda fuction whenever the file is uploaded.
S3 Glacier
You cannot directly upload files to Glacier through S3 console
Retrieval
- Expedited Retrieval
- Expedited retrievals allow you to access data in 1-5 mins.
- Expedited retrievals allow you to quickly access your data when occassional urgent requests for a subnet of archives are required
- Standard Retrieval
- need 3-5 hours
- Bulk Retrieval
- need 5-12 hours
- Expedited Retrieval
Vault Lock
- S3 Glacier Vault Lock allows you to easily deploy and enforce compliance controls for individual S3 Glacier vaults with a vault lock policy.
- You can specify controls such as “write once read many” (WORM) in a vault lock policy and lock the policy from the future edits.
- Once locked, the policy can no longer be changed.
Objects in Glacier Deep Archive
- You cannot directly move objects to another storage class. These need to be restored first & then copied to the disired storage class.
- S3 Glacier console can be used to access vaults and objects in them. But is cannot be used to restore the objects.
Athena
- charged per query and amount of data scanned
- for SSE-KMS, Athena can determine the proper materials to decrypt the dataset when creating the table. You do not need to provide the key information to Athena.
- Athena can create the table for the S3 data encryption by SSE-KMS
- Workgroup
- A separate Workgroup can be created based upon users, teams, applications or workloads. This will minimize the amount of data scanned for each query, improve performance and reducing cost.
- Using Workgroup to isolate queries for teams, applications, or different workloads.
Route 53
is a global service, not regional
is highly available and scalable DNS web service. You can use Route 53 perform three main functions
- Register domain names
- Route internet traffic to the resources for your domain
- Check the health of your resources
Route 53 is not used for load-balancing traffic among individual resource instances
Record Type
- A: convert to an IPv4 address
- AAAA: convert to an IPv6 address
- CNAME: convert to another hostname
- only for non root domain
- Alias: convert to a specific AWS resource
- works for root domains and subdomains
- free of charge
- native health check
Alias Records for your domain and subdomain
- Instead of using IP addresses, the alias records use S3 website endpoints.
- S3 maintains a mapping between the alias records and the IP addresses where S3 buckets reside.
- A record set can only have one Alias Target
DNS TTL
- it enables the client to cache the response of a DNS query
Routing Policy
- Simple Routing Policy
- if you set multiple values, it will return a random one
- using command(dig) will find multiple values returned
- can’t attach a Health Check
- Weighted Routing Policy
- only see one value returned, not multiple values
- can attach a Health Check
- Latency Routing Policy
- Failover Routig Policy
- must attach a Health Check
- Choose one for primary, and another for secondary
- GeoLocation Routing Policy
- Multi Value Routing Policy
- Multi Value almost like Simple Policy, the only diff is the Healch Check
- Simple Routing Policy
Traffic can route to the following services
- CloudFront
- EC2
- Beanstalk
- ELB
- RDS
- S3
- WorkMail
Reasons for displaying “Server not found” error
- You didn’t create a record for the domain or subdomain name
- You created a record but specified the wrong value
- The resource that you’re routing traffic to is unavailable
Logging and Monitoring Route 53
Monitoring Health Checks using CloudWatch
- By default, metric data for Route 53 health checks is automatically sent to CloudWatch at 1m intervals
Monitoring Domain Registrations, including
- Status of new domain registrations
- Status of domain transfers to Route 53
- List of domains that are approaching the expiration date
Logging Route 53 API calls with CloudTrail
Types of Route 53 Health Checks
- Health Checks that monitor an endpoint
- Health Checks that monitor other health checks
- Health Checks that monitor CloudWatch alarms
There is no interface endpoint for Route 53
Route 53 is not inside the AWS backbone
ELB
An ELB must have at least two AZs, and ELB can’t cross region
Types of ELB
- ALB
- Layer 7
- WAF can be attached to ALB
- SG can attach to it
- ALB do not have the spot type
- Target Groups:
- EC2 instance
- ECS tasks
- Lambda functions
- IP addresses
- ALB can route to multiple target groups
- The application must check X-Forward-For in HTTP request header for requiring IP address of users
- ALB does not charge users based on the number of enabled AZs
- Support dynamic mapping
- NLB
- Layer 4 (Transport)
- SG cannot attach to it
- Support dynamic mapping
- Gateway LB
- Layer 3 (Network)
- CLB (legacy)
- It does not support dynamic mapping
- ALB
Troubleshooting
- LB shows 503 means there is no registered target
- if LB cannot connect to your application, please check SG
Load Balancer Stickiness
- Works for ALB and CLB
- Use case: make sure users don’t lose their session data
Cross Load Balancing
- ALB
- Always on
- no charge for inter AZ data
- NLB
- default off
- you pay inter AZ data if enable
- CLB
- no charge for inter AZ data if enable
- ALB
SSL/TLS
- using SNI to resolve multiple SSL certificates onto one web server
- only works for ALB & NLB, CloudFront
- for CLB, must use multiple CLB for different hostnames
TLS listeners
To use a TLS listener, you must deploy at least one server certificate on your load balancer. The load balancer uses a server certificate to terminate the front-end connection and then to decrypt requests from clients before sending them to the targets
ELB uses a TLS negotiation configuration, known as security policy, to negotiate TLS connections between a client and the load balancer.
A security group is a combination of protocols and ciphers.
The protocol establishes a secure connection between a client and a server and ensures that all data passed between the client and your load balancer is private.
A cipher is an encryption algorithm that uses encryption keys to create a coded message.
NLB does not support a custom security policy
NLB requires one certificate per TLS connection to encrypt traffic between client & NLB annd forward decrypted traffic to target servers. Using AWS Certificate Manager is a preferred option, as these certificates are automatically renewed on expiry
Connection Draining
- when existing connection shows unhealthy, the users must wait the response, and this period means draining mode. The new requests from other users will
- redirect to other targets.
- If you set draining value is 0, it means the connection will be droped, and the user will receive an error from ELB
- CLB: names Connection Draining
- ALB & NLB: in Target Group and names Deregistration Delay
ELB rules of Traffic
- Listener: incoming traffic is evaluated by ports
- Rules: listener then will invoke rules to decide what to do with the traffic
- Target Groups
- Health Check
- ELB doesn’t terminate unhealthy instances, it just redirect traffic to the healthy one
- for NLB and ALB, Health Checks locate in Target Group
- Monitor ALB
- CloudWatch metrics
- Access logs
- Request tracing
- CloudTrail logs
Reasons for connection failure of Internet-facing load balancer
- Your internet-facing load balancer is attached to a private subnet
- A SG or NACL does not allow traffic
Target Health Status of a Registered Target
- Initial
- Healthy
- Unhealthy
- Unused
- draining (deregistration)
Reasons for unhealthy
- A Security Group of the instance does not allow traffic
- NACLs does not allow traffic
- The ping path does not exist
- The connection times out
- The target did not return a successful response code
Target Type (you cannot change its target type)
- instance
- The targets are specified by instance ID
- ip
- The targets are specified by IP address
- You can’t specify publicly routable IP addresses
- If you specify targets using an instance ID, traffic to instances using the primary private IP address specified in the primary network interface for the instance
- If you specify targets using IP addresses, you can route traffic to an instance using any private IP address from one or more network interfaces.
- instance
Integration with ECS (Dynamic Mapping)
- Since ALB/NLB supports dynamic mapping. We can configure the ECS service to use the load balancer, and a dynamic port will be selected for each ECS task automatically. With Dynamic mapping, multiple copies of a task can run on the same instance
ELB + ASG is good for fault tolerance
- Using ELB with ASG, both should be in the same region and launch in the same VPC.
CloudWatch metrics
- Latency
- The total time elapsed, in seconds, from the time the load balancer sent the request to a registered instance until the instance started to sennd the response headers.
- RequestCount
- The number of requests completed or connections made during the specified interval
- Latency
CloudFront
CDN
For improving read performance, content is cached in the Edge Location
can integrate with Shield and WAF for DDoS protection
can expose HTTPS and can talk to internal HTTPS backends
It can be used to cache web content from the origin server to provide users with low latency access, and offload origin server loads
For files less than 1 Gb, using CloudFront would provide better performance than S3 Transfer Acceleration
CloudFront Origins
S3 Bucket
- cache content at the edge
- enhanced security with Cloud Origin Access Identity (OAI)
- can be as an ingress
Custom Origin(HTTP)
ALB
EC2
S3 website
Route 53
any HTTP backend
Distribution
A collection of Edge Locations
CloudFront vs S3 CRR
- CloudFront
- great for static content
- files cached for a TTL
- S3 CRR
- great for dynamic content
- near real-time
- only read
- CloudFront
OAI (Origin Access Identity)
Using OAI to restrict S3 to be accessed only by this identity
Signed URL
Using SDK API to generate Signed URL for restricting visit.
Signed URL to CloudFront, and OAI to S3 can create a simple media sharing website.
- Signed URL: Access to one file
- Signed Cookie: Access to a bunch of files
The data transfer out to the internet or origin is not free. Adifferent rate is charged depending on the region.
Data transfer from origin to CloudFront Edge Locations is free
Because for each custom SSL certificate associated with one or more CloudFront distributions using the Dedicated IP version of custom SSL certificate support, you are charged at $600 per month
If you want to increase the cache durationn for certain contents, you can add a Cache-Control header to control how long the objects stay in the CloudFront cache
Error page can be customized through CloudFront
Invalidating
- Invalidating the object removes it from the CloudFront edge cache to return the correct file to the user.
Redirect HTTP to HTTPs
- Configure the Viewer Protocol Policy of the CloudFront distribution to be “Redirect HTTP to HTTPs”
If you run PCI or HIPAA-compliant workloads based on the AWS Shared Responsibility Model, we recommend that you log your CloudFront usage data for the last 365 days for future auditing purpose. To log usage data, you can do the following
- Enable CloudFront access logs
- Capture requests that are sent to the CloudFront API
Query String Forwarding
- CloudFront Query String Forwarding only supports Web distribution. For query string forwarding, the delimiter character must always be a “&” character. Parameters’ names and values used in the query string are case sensitive. Parameter Names and Values should use the same case.
Global Accelerator
- For global users to access application that deployed in AWS, minimize latency and provide a straight connection to AWS resources
- Unicast IP vs Anycast IP
- Unicast IP: one server holds one IP address
- Anycast IP: all servers hold the same IP address and clients are routed to the nearest one
- Global Accelerator using Anycast IP
- 2 Anycast static IP addresses are created for your application
- Anycast IP send traffic to the Edge Location, then Edge Location send traffic to ALB or something else
- Improve performance and availability of the application
- Works with Elastic IP, EC2, ALB, NLB, public or private
- No caching
- DDoS protection by Shield
- Global Accelerator vs CloudFront
- Same
- Using Edge Locations around the world
- Integrate with Shield for DDoS
- Diff
- GA
- great for application serving global users
- all requests redirect from Edge Locations to AWS services, no caching
- great for TCP and UDP
- fast regional failover
- CloudFront
- great for static and dynamic content
- content is cached at the Edge Location
- GA
- Same
API Gateway
Support for WebSocket protocol
Handle API versioning
Handle different environments
Handle authentication and authorization
Handle request throttling
Cache API response
- Default TTL value for API Caching: 300s
- Maximum TTL value: 3600s (60m)
Integration Type
- Lambda
- Easy way to expose REST API backed by AWS Lambda
- HTTP
- Expose HTTP endpoints in the backends (HTTP API on premises, ALB)
- AWS Services
- Expose any AWS API through API Gateway (Step Function workflow, SQS)
- Mock
- VPC Link
- A way to connect to the resources within a private VPC
- Lambda
Endpoint Types
- Edge-Optimized (default): for global users
- through Edge Location
- API Gateway still lives in one region
- Regional: for clients within the same region
- Cloud manually combine with CloudFront (more control on caching strategies and distribution)
- Private
- Can only be accessed from VPC using ENI
- Edge-Optimized (default): for global users
Endpoint Integration inside a Private VPC
- You can also now use API Gateway to front APIs hosted by backends that exist privately in your own data centers, using AWS Direct Connect links to your VPC.
Authentication & Authorization
IAM Permissions
- Good for Authentication + Authorization
- For authorizing users which are inner ones
- Using Sig v4 capacity where IAM credentials are in headers
Lambda Authorizer (formerly Custom Authorizer)
- Good for Authentication + Authorization
- Using Lambda to verify token in headers being passed
- Option to cache result of authentication
- Helps to use OAuth / SAML / 3rd party type of authentication
- Lambda must retun an IAM policy for the user
Cognito User Pools
- Cognito helps with Authentication, not Authorization
- Cognito fully managed user lifecycle
- API Gateway automatically verify
Throttling Limit Setting
- Server-side throttling limits are applied across all clients. These limit settings exist to prevent your API
- Per-client throttling limits are applied to clients that use API keys associated with your usage policy as client identifier
Accout-level throttling per Region
- When request submissionns exceed the steady-state request rate and burst limits, API Gateway fails the limit-exceeding requests and returns 429 Too Many Request errors responses to the client.
- Burst limit corresponds to the maximum number of concurrent request submission that API Gateway can fulfill at any moment.
- Ex: given a burst limit of 5,000 and account-level rate limit of 10,000 request per second in the Region
- If the caller sends 10,000 in the first millisecond, API Gateway serves 5,000 of those reuqests and throttles the rest in the one-second period
Usage Plan
- A Usage Plan is a set of rules that operates as a barrier between the client and the target of the API Gateway. This set of rules be applied to one or more APIs and stages
- API Key must be associated with a usage plan, one or more; otherwise, it will not be attached to any API. Once attached, the API keys are applied to each API under the usage plan.
- API Key feature useful to filter unsolicited requests. It’s not a proper way to apply authorization to the API method
- Client put api key in request header “x-api-key”
Mehtod Level Throttling can override Stage Level Throttling in a Usage Plan
Controlling Access to an API in API Gateway
- Resource Policies
- Using resource policies to allow your API to be securely invoked by
- Users from a specified AWS account
- Specified source IP address ranges or CIDR blocks
- Specified VPC or VPC endpoints
- API Gateway resource policies are attached to resources, while IAM policies are attached to IAM entities
- Using resource policies to allow your API to be securely invoked by
- Standard AWS IAM roles and policies
- CORS
- Lambda Authorizers
- Amazon Cognito User Pools
- Client-side SSL Certificates
- Can be used to verify that HTTP requests to your backend system from API Gateway
- Usage Plans
- Resource Policies
Security Measures
- API Gateway supports throttling settings for each method in your APIs, you can set a standard rate limit and a burst limit per second for each method in your REST APIs. Further, API Gateway automatically protects your backend sysetems from distributed denial-of-service (DDoS) attacks, whether attacked with counterfeit requests (Layer 7) or SYN floods (Layer 3)
In Cache settings, the actions that you can do manually
- Flush entire cache
- Change cache capacity
- Encrypt cache data
Logs
CloudWatch Logs
- Loged data includes errors or execution traces (such as request or response parameter values or payloads)
Access Logging
- In access logging, as an developer, want to log who has accessed your API and how the caller accessed the API. You can create your own log group or choose an existing one, which could be managed by API Gateway
Permissions
- Controlling access to API Gateway with IAM permissions by controlling access to the two API Gateway component processes
- Management Component
- create, deploy, and manage an API in API Gateway
- must grant the API developer permissions
- Execution Component
- call a deployed API or refresh teh API caching
- must grant the API caller permissions
- Management Component
- Controlling access to API Gateway with IAM permissions by controlling access to the two API Gateway component processes
RDS
RDS Backups
- Automated Backups
- daily full backup of the database (during the maintenance window)
- every 5 minutes backup transaction logs
- 7 days retention
- Storage I/O may be suspended during backup
- DB Snapshots
- Automated Backups
During automated backup, RDS creates a storage volume snapshot of the entire Database Instance. RDS uploads transaction logs for DB instances to S3 every 5 mins. To restore DB instance at a specific point in time, a new DB instance is created using DB snapshot.
If you disable automated backups, it disables point-in-time recovery.
RDS Read Replicas
- Up to 5 Read Replicas
- Within AZ, Cross AZ or Cross Region
- Replicas are ASYNC, so reads are eventually consistent
- Read Replicas can be promoted to DB
- Use case: split workload for BI, data analytics, etc…
- If you create your Read Replicas in another AZ, you need to pay connection fee between different AZs
RDS Multi AZ (DR)
- SYNC Replication
- One DNS Name - automatic failover to standby
- Read Replicas be setup as Multi AZ for DR
- provide enhanced availability and durability for DB instances.
RDS Encryption
- at rest encryption
- Using KMS and defined at launch time
- If the master don’t encrypt, read replicas also can’t be encrypted
- Transparent Data Encryption (TDE) is available for Oracle and SQL Server
- in-flight
- Using SSL to enforce SSL (PostgreSQL by set value, and MySQL by typing SQL command)
- at rest encryption
IAM database authentication
- works with MySQL and PostgreSQL
- You don’t need a password, just an authentication token obtained from IAM and RDS API calls
- Auth token has a lifetime of 15 minutes
RDS Failover Mechanism
- Failover mechanism automatically changes the DNS CNAME record of the DB instance to point to the standby DB instance
Solution for Read-Heavy
- read replicas
- ElastiCache
- Sharding the dataset
Solution for too many PUT
- Creating an SQS queue and store these PUT requests in the message queue and then process it accordingly
- DB Parameter Groups
- You manage your DB engine configuration through the use of parameters in a DB parameter group.
- DB parameter groups act as a container for engine configuration values that are applied to one or more DB instances.
- A default DB parameter group is created if you create a DB instance without specifying a customer-created DB parameter group.
- You can’t modify the parameter settings of a default DB parameter group. You must create your own DB parameter group to change parameter settings from their default value
- If you want to use your own DB parameter group, you simple create a new DB parameter group, modify the desired parameters, and modify your DB instance to use the new DB parameter group
Aurora
- Aurora cost more than RDS (20% more) - but is more efficient
- Data is hold in 6 replicas, across 3 AZs
- Auto healing capability
- Multi AZ, auto scaling read replicas
- Aurora database can be global for DR or latency purpose
- Auto scaling storage from 10GB - 64TB
- Aurora Serverless Option
- Support for CRR
- Aurora can span multiple regions by Aurora Global Database
DynamoDB
Highly avaialbe with replication across 3 AZs
Distributed NoSQL database
Integrate with IAM for authentication and authorization
Enable event driven progarmming with DynamoDB Streams
Features
- DynamoDB is made of tables
- each table has a primary key
- each table has a infinite number of items
- each item has attributes
- max size of item is 400KB
Provisioned Throughputs
- Table have provisioned read and write capacity units
- Read Capacity Unit (RCU): throughput for reads
- 1 RCU = 1 strongly consistent read of 4KB per second
- 1 RCU = 2 eventually consistent read of 4KB per second
- Write Capacity Unit (WCU): throughput for writes
- 1 WCU = 1 write of 1KB per second
- Option to setup auto-scaling of throughput
- Throughput can be exceeded temporarily using “burst credit”
- If burst credit are empty, you’ll get a “ProvisionedThroughputException”
DynamoDB Accelerator (DAX)
- Seamless cache for DynamoDB, no application re-write
- Writes go through DAX to DynamoDB
- Solves the Hot Key Problem
- 5 minutes TTL for cache by default
- up to 10 nodes in the cluster
- Multi AZ
DynamoDB Streams
It can monitor the changes to a DynamoDB table.
this stream can be read by Lambda, and then we can do
- react to changes in real time
- analytics
- create derivative tables/views
- insert into ElasticSearch
using Streams to implement CRR
Stream has 24 hours of data retention
When you enable DynamoDB Streams on a table, you can associate the stream ARN with a Lambda function that you write. Immediately after an item in the table is modified, a new record appears in the table’s stream. Lambda polls the stream and invokes your Lambda function synchronously when it detects new stream records.
Transaction
- Coordinate with Insert, Update, Delete across multiple tables
- Include up to 10 unique items or up to 4 MB of data
On Demand Option
- No capacity planning needed (WCU/RCU) - scales automatically
- 2.5x more expensive than provisioned capacity
- Global Tables
- Multi region, fully replicated, high performance
- Must enable DynamoDB Streams
- Useful for low latency, DR purposes
- Capacity Planning
- Planned capacity: Provisioned WCU & RCU, can enable auto scaling
- On-demand capacity: get unlimited WCU & RCU, no throttle, more expensive
- DMS can migrate data from Mongo, Oracle, MySQL, S3, etc… to DynamoDB
- Better for storing metadata
- It doesn’t have the feature of Read Replica
- Auto Scaling
- With DynamoDb Auto Scaling, it can automatically increase its write capacity for the spike and decrease the throughput after the spike.
- It’s good for applications where database utilization cannot be predicted.
- It can help to scale dynamically to any load for both DynamoDB tables and Global Secondary Index
Lambda
Pay per request and compute time
Lambda is good for running code, not packaging
Lambda Limits - per region (apply to configuration, deployments, and execution)
- Function Memory allocation
- 128MB - 3008MB (64MB increments)
- Function Timeout
- 900s (15m)
- Function Environment Variables
- 4KB
- Function Resource-based Policy
- 20KB
- Function Layers
- 5 layers
- Function burst concurrency
- 500 - 3000 (varies per Region)
- Invocation Payload (request and response)
- 6 MB (synchronous)
- 256 KB (asynchronous)
- Deployment Package
- 50 MB (zipped)
- 256 MB (unzipped)
- Disk
- Disk capacity: 512MB
- Can use /tmp directory (500MB) to load other files at startup
- Function Memory allocation
Lambda@Edge
- Use case
- When you want to run a global AWS Lambda, and build more responsive applications
- Implement request filtering before reaching your application
- Viewer request
- Origin request
- Origin response
- Viewer response
- Website Security and Privacy
- Dynamic Web Application at the Edge
- SEO
- A/B Testing
- User Prioritization
- User Tracking and Analytics
- User Authentication and Authorization
- Lambda@Edge function does provide the capability to cutomize content. Lambda@Edge allows users to run their own Lambda functions to customize the content that CloudFront delivers, executing the functions in AWS Regions close to the viewer. Lambda functions runn in response to CloudFront events, without provisioning or managing servers.
- Use case
By default Lambda run in No VPC
Disadvantage for Serverless services: Cold Start
Lambda funcntion environment variables are used to configure additional parameters that can be pssed to lambda function
Services that invoke Lambda Functions Synchronously
- ELB (ALB)
- Cognito
- API Gateway
- CloudFront (Lambda@Edge)
- Kinesis Firehose
- Step Functions
- S3 Batch
- Lex
- Alexa
Services that invoke Lambda Fuctions Asynchronously
- S3
- SNS
- SES
- CloudFormation
- CloudWatch Logs
- CloudWatch Events
- CodeCommit
- CodePipeline
- Config
- IoT
- IoT Events
Lambda supports the following poll-based services
- Kinesis
- DynamoDB
- SQS
- Debugging and error handling
For asynchronous invocation
If you don’t specify a DLQ for failed event, this event will be discard after several failed retries
DLQ Resources
- SNS
- SQS
If your functions runs out of memeory, the Linux kernel will kill your process immediately. There is no supported way at this time to catch and handle this error either.
When using Lambda, you are only responsible for your code. AWS will perform provisioning capacity, monitoring, deploying your code and logging on your behalf.
Lambda event source mappings support SQS standard and SQS FIFO
Event Source Options
- Enabled
- A flag to signal Lambda that it should start polling your SQS queue
- EventSourceArn
- The ARN of your SQS queue that Lambda is monitoring for new messages
- FunctionArn
- The Lambda function to invoke
- BatchSize
- The number of records to send to the function in each batch. For a standard queue this can be up to 10,000 records. For a FIFO queue the maximum is 10.
- Enabled
You can also invoke a Lambda function by Lambda’s invoke API.
When you updating a Lambda function, there will be a brief window of time, typically less than a minute, when requests could be served by either the old or the new version of your function.
Lambda Function ARN
- Qualified ARN - with version suffix
- arn:aws:lambda:aws-region:acct-id:function:helloworld:$LATEST
- Unqualified ARN - without version suffix
- arn:aws:lambda:aws-region:acct-id:function:helloworld
- You cannot use Unqualified ARN to create an alias.
- This Unqualified ARN will invoke a LATEST version
- Qualified ARN - with version suffix
Lambda Alias
- Invokers don’t need to change Lambda ARN when usig Lambda Alias, creators just need to remap Lambda Alias to a new version of Lambda after publishing a new version
Publishing Lambda
- When you publish a version, Lambda makes a snapshot copy of the Lambda function code (and configuration) in the $LATEST version. A published version is immutable (both code and configuration).
Version numbers are never reused, even for a function that has been deleted and recreated
Not recommended for using $LATEST ARN in PRODUCTION mode, there are chances that the configuration can be meddled and can cause unwanted issues.
Function Policy
- Grant cross-account permissions (not on the execution role policy)
- function policy cannnot be edited from the AWS console (using either CLI or SDK)
Lambda accessing Private VPC
- If your Lambda function accesses a VPC, you must make sure that your VPC has sufficient ENI capacity to support the scale requirements of your Lambda function. Using formula to determine the ENI capacity
- Peak cocurrency executions = Peak Requests per Second * Average Function Duration (in seconds)
- ENI capacity = Projected peak concurrent execution * (Memory / 3 GB)
Enviroment Variable Encryption
- By default, all data in environment variables are encrypted by KMS, then automatically decrypted to Lambda code. (not encrpted during deployment process, only after deployment)
- Using encryption helper and decryption helper to encrypted and decrypted sensitive data during deployment
AWSLambdaBasicExecutionRole
- Grants permissions only for CloudWatch Logs actions to write logs
- Contains
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
CloudWatch metrics for Lambda
- Dead Letter Error
- Duration
- Invocation
Memory
Ensuring version of Lambda in the code
- Using Method
- getFunctionVersion()
- Using Environment Variables
- AWS_LAMBDA_FUNCTION_VERSION
- Using Method
Errors for the response of Lambda
- Synchronous invocation
- response header: X-Amz-Function-Error
- The status code is 200 for function error
- Asynchronous invocation
- Stored in DLQ if you specified a DLQ for errors
- Synchronous invocation
Users are charged based on the number of requests and the time it taks for the code to execute.
The duration price depends on the amount of memory allocated to the function.
Lambda function’s cost will be reduced if the execution duration decreases
CloudWatch
- CloudWatch Metrics
- Dimension is an attribute of metric (instance ID, environment, etc…)
- Up to 10 dimensions per metric
- Metrics have timestamps
- Metrics belong to namespaces
- EC2 instance metrics can monitor “every 5 minutes”, and you can also change to “every 1 minute”
- Using detailed monitoring if you want to prompt scale your ASG in EC2
- EC2 memory usage must be created for Custom Metrics
- Custom Metrics
- Standard: 1 minutes
- High resolution: up to 1 second, but higher cost
- Use API called PutMetricData and Use exponential back off in case of throttle errors
- Dashboards
- Dashboards are global, can include graphs from different regions
- CloudWatch Logs
- CloudWatch can collect log from
- Elastic Beanstalk
- ECS
- AWS Lambda
- VPC Flow Logs
- API Gateway
- CloudTrail based on filter
- CloudWatch log agents: ex. EC2
- Route 53: Log DNS queries
- can go to
- to S3 for archive
- to ElasticSearch for further analytics
- encrytion using KMS
- CloudWatch can collect log from
- CloudWatch Logs Insights: can be used to query logs and queries to CloudWatch Dashboards
- CloudWatch Logs Agent vs CloudWatch Unified Agent
- Logs Agent
- Old version
- Can only send to CloudWatch Logs
- Unified Agent
- Collect additional system level metrics such as RAM, processes, etc…
- Centralized configuration using SSM Parameter Store
- Logs Agent
- CloudWatch Unified Agent - Metrics
- CPU
- Disk metrics
- RAM
- Netstat
- Processes
- Swap Space
- CloudWatch Alarm
- trigger notification for any metrics
- Alarm can used for
- ASG
- EC2 Action
- SNS notification
- Alarm States
- OK
- INSUFFICIENT_DATA
- ALARM
- Period
- High resolution custom metrics: can only choose 10 sec or 30 sec
- CloudWatch Events
- Schedule: Cron jobs
- Event Pattern: Event rules to react to a service doing something
- Trigger to
- Lambda
- SQS
- SNS
- Kinesis Messages
- When target is Lambda, the inputs can be
- Matched event
- Part of the matched event
- Constant (JSON text)
CloudTrail
- Provides governance, compliance and audit for your AWS account
- CloudTrail is enable by default
- Get an history of events / API calls made within your AWS account by
- Console
- SDK
- CLI
- AWS Services
- To ensure logs have nont tampered with you need to turn on Log File Validation
- CloudTrail can be set to log across all AWS accounts in an organization and all regions in an account
- CloudTrail will deliver log files from all regions to S3 bucket and an optional CloudWatch Logs log group you specified.
- Two types of events
- Management Events
- Tracks management operations, turn on by default
- Data Events
- Tracks specific operations for specific AWS services, turn off by default
- Management Events
- By default, CloudTrail event log files are encrypted using S3 server-side encryption (SSE-S3). You can also choose to encrypt your log files with an KMS key.
- Log File Integrity
- After you enable CloudTrail log file integrity, it will create a hash file called digest file, which refers to logs that are generated. The Digest file can be validated using the public key. This feature ensures that all the modifications made to CloudTrail log files are recorded.
- Global Service Events Logging
- For most services, events are recorded in the region where the action occurred.
- For Global services such as IAM, and CloudFront, events are delivered to any trail that includes global services
- For most global services, events are logged as occurring in US East (N. Virginnia) Region, but some global service events are logged as occurring in other regions, such as US East (Ohio) Region or US West (Oregon) Region.
- If you change the configuration of a trail from logging all regions to logging a single region, global service event logging is turned off automatically for that trail
- For eliminating duplicate logs in all regions, you can disable Global Service Event in all regions and enable them in only one region
SQS
Unlimited throughputs, unlimited number of messages in queue
Default retention of messages: 4days, maximum is 14 days
Low latency ( < 10ms on publish and receive)
Limitation of 256KB per message sent
It helps in horizontal scaling of AWS resources and is used for decoupling systems.
SQS Access Policies
- Useful for cross-account access to SQS queues
- Useful for allowing other services (SNS, S3…) to write to an SQS queue
Message Visibility Timeout
- After a message is pulled by a consumer, it becomes invisible to other consumers
- By default, the “message visibility timeout” is 30 seconds, 12 hours maximum
- A consumer could call the “ChangeMessageVisibility” API to get more time
Dead Letter Queue
- Make sure to process the messages in the DLQ before they expire (Good to set a retention of 14 days in the DLQ)
Delay Queue
- Delay a message up to 15 minutes
- Default is 0 seconds
- Can set a default at queue level
Standard Queue
- Unlimited number of transactions per second
FIFO Queue
- Limited throughput: 300 msg/s without batching, 3000 msg/s with
- Exactly-once send capability
Queuing vs Streaming
- Queuing
- Generally will delete messages once they are consumed
- Not real-time
- have to pull
- Streaming
- Multiple consumers can react to events
- Event live in the stream for long periods of time, so complex operations can be applied
- Real-time
- Queuing
Amazon SQS Extended Client Library for Java
- Lets you send messages 256KB to 2GB in size
- The message will be stored in S3 and library will reference the S3 object
Short Polling vs Long Polling
- Short Polling (default)
- When you need a message right away, short polling is what you want
- Long Polling (most used)
- Maximum 20 seconds
- reduce cost
- Benefits for Long Polling
- Eliminate empty responses
- Eliminate false responses
- Return messages as soon as they become available
- Short Polling (default)
SQS doesn’t delete messages automatically
Permission exist on the Queue level, not on the message level
SQS Batch Actions
- To reduce costs and manipulate up to 10 messages with a single action, you can use the following actions
- SendMessageBatch
- DeleteMessageBatch
- ChangeMessageVisibilityBatch
- To reduce costs and manipulate up to 10 messages with a single action, you can use the following actions
DeleteMessage
- Deletes the specifed message from the specified queue. Using the ReceiptHandle of the message (not the MessageId which you receive when you send the message)
SQS Encryption
- SQS does not encrypt messages by default. You need to enable encryption on the Queue messages.
How to process data with priority
- Use two SQS queues, one for high priority messages and the other for default priority. The high priority queue can be polled first.
Queue Size Metrics
- ApproximateNumberOfMessagesVisible describes the number of messages available for retrieval. It can be used to decide the queue length.
Increasing Throughput
SQS queues can deliver very high throughput.
Horizontal Scaling
- To achieve high throughput, you must scale message producers annd consumers horizontally (add more producers and consumers)
- Horizontal scaling involves increasing the number of message producers and consumers in order to increase your overall queue throughput. You can scale horizontally in three ways
- Increase the number of threads per client
- Add more client
- Increase the number of threads per client and add more clients
Action batching
- Batching performs more work during each round trip to the service.
SNS
All messages published to SNS are stored redundantly across multiple AZs
It’s a real-time notification.
Integrate with AWS services
- CloudWatch (for alarms)
- ASG notification
- S3 (on bucket events)
- CloudFormation (upon state changes)
Publish
- Topic Publish (using SDK)
- Create a topic
- Create a subscription (or many)
- Publish to the topic
- Direct Publish (for mobile apps SDK)
- Create a platform application
- Create a platform endpoint
- Publish to the platform endpoint
- Works with Google GCM, Apple APNS, Amazon ADM, etc…
- Topic Publish (using SDK)
SNS Access Policies
- Useful for cross-account access to SNS topics
- Useful for allowing other services to write to an SNS topic
SQS + SNS: Fan Out
- Push once in SNS, receive in all SQS queues
- Fully decoupled, no data loss
- SQS allows
- data persistence
- delayed processing
- retries of work
- Make sure your SQS queue access policy allows for SNS to write
- SNS cannot send messages to SQS FIFO queues (AWS Limitation)
- Use Case
- S3 Events to multiple queues (if you want to send the same S3 event to many SQS queues, use fan-out)
Subscribers do not pull for messages (not like SQS)
Messages are instead automatically and immediately pushed to subscribers
SNS Topic
- Topic allows you to group multiple subscriptions together
- When topic deliver messages to subscribers it will automatically format your message according to the subscriber’s chosen protocol
- A topic is able to deliver to multiple protocol at once
- HTTP and HTTPS: create web hooks into your web application
- Email-JSON
- SQS
- Lambda
- SMS
- Platform application endpoint: Mobile Push
Delivery protocols for receving notification from SNS
- HTTP
- HTTPS
- Email-JSON
- SQS
- Application
- Lambda
- SMS
- SNS Message Filtering - Using Filter Policy
By default, a subscriber of an Amazon SNS topic receives every message published to the topic. A subscriber assigns a filter policy to the topic subscriptionto receive only a subset of the messages. A filter policy is a simple JSON obiert. The policy contains attributes that define which messages the subscriber receives.
- Message Attribute Items
- Name
- Type
- Value
MessageId
Messaging
- Two patterns of application communication
- Sync: can be problematic if there are sudden spikes of traffic
- Async
- SQS: queue model
- SNS: pub/sub model
- Kinesis: real-time streaming model
KMS
- Integrate with
- EBS
- S3
- Redshift
- RDS
- SSM - Parameter Store
- KMS can help in encrypting up to 4KB of data per call, if data > 4KB, use envelope encryption
- Envelope Encryption
- Encrypt your data key by your Customer CMK, then delete plain text data key. Keep encrypted data key and encrypted data stored in S3.
- When you need to decrypt data in S3, you first decrypt your data key by your CMK, then decrypt data by decrypted data key.
- If data is more than 4KB, using Envelope Encryption
- Three types of CMK
- AWS Managed Service Default CMK: free
- User Keys created in KMS: $1 / month
- User Keys imported (must be 256-bit symmetric key): $1 / month
- To give access to KMS to someone
- Make sure the Key Policy allows the user
- Make sure the IAM Policy allows the API calls
- KMS is regional specific. When you copy snapshot over, you need to re-encrypt your snapshot with a new key
- Keys are not transferrable out of the region they were created in. Keys are also region-specific.
- KMS Key Policies
- Control access to KMS keys
- You cannot control access without Key Policy
- Default KMS Key Policy
- Created if you don’t provide a specific KMS Key Policy
- Complete access to the key to the root user = entire AWS account
- Give access to the IAM policies to the KMS key
- Custom KMS Key Policy
- Define users, roles that can access the KMS key
- Define who can administer the key
- Useful for cross-account access of your KMS key
- Unauthorized KMS master key permission error
- In the KMS key policy, assign the permission to the application to access the key
- Key Rotation
- KMS will rotate keys annually and use the appropriate keys to perform cryptographic operations.
CLI & SDK
- Access Key ID and Secret Access Key are collectively known as AWS Credentials
CloudFormation
- For reducing cost:
- You can estimate the costs of your resources using the CloudFormation template
- Saving strategy: In dev, you could automatically delete templates at 5PM and recreate at 8AM, safely
- You can many stacks for many apps, and many layers
- Templates have to be uploaded in S3 and then referenced in CloudFormation
- To update a template, you can’t update it, you have to re-create a new version of that template
- Tempaltes Components
- Resources (Mandatory)
- Parameters: dynamic inputs for your template
- Mappings: the static variables for your template
- Outputs
- Conditionals
- Metadata: additional information about template
- When CloudFormation encounters an error, it will rollback with ROLLBACK_IN_PROGRESS
- CreationPolicy
- CreationPolicy is invoked only when CloudFormation creates the associated resource.
- The resources that support CreationPolicy
- AppStream::Fleet
- AutoScaling::AutoScalingGroup
- EC2::Instance
- CloudFormation::WaitCondition
- DeletionPolicy
- DeletionPolicy attribute
- With the DeletionPolicy attribute you can preserve, and in some cases, backup a resource when its stack is deleted. You specify a DeleteionPolicy attribute for each resource that you want to control. If a resource has no DeletionPolicy attribute, CloudFormation deletes the resource by default
- If you want to modify resources outside of CloudFormation, use a retain policy and then delete the stack. Otherwise, your resources might get out of sync with your CloudFormation template and cause stack errors
- DeletionPolicy options
- Delete
- the defualt DeletionPolicy of the most services is delete. It means CloudFormation will delete the resources and its content during stack deletion
- But some services are not
- RDS::DBCluster resources, default is Snapshot
- RDS::DBInstance resources, default is Snapshot
- S3 buckets, you must delete all objects in the bucket for deletion to succeed
- Retain
- Keeps the resource without deleting the resource or its content when its stack is deleted.
- Snapshot
- CloudFormation will create a snapshot for the resource before deleting it
- Resources that support snapshots
- EC2::Volume
- ElastiCache::CacheCluster
- ElastiCache::ReplicationGroup
- Neptune::DBCluster
- RDS::DBCluster
- RDS::DBInstance
- Redshift::Cluster
- Delete
- DeletionPolicy attribute
- Parameters on Template
- OnDemandPercentageAboveBaseCapacity
- SpotMaxPrice
- determine the maximum price that you are wiling to pay for Spot Instances
- Dirft Detection
- CloudFormation Dirft Detection can be used to detect changes made to AWS resources outside the CloudFormation Templates.
- It does not determine drift for property values that are set by default. To determine drift for these resources, you can explicitly set property values that can be the same as that of the default value.
- Resolving drift helps to ensure configuration consistency and successful stack operations
- CloudFormation Template
- A tempalte is a JSON- or YAML- formatted text file that describes your AWS infrastructure.
- Items
- Resources
- The required Resources section declares the AWS resources that you want to include in the stack, such as EC2 instance or S3 bucket
- Parameters
- Use the optional Parameters section to cutomize your templates. Parameters enable you to input custom values to your template each time you create or update a stack.
- Outputs
- The optional Outputs section declares output values that you can import into other stacks, return inn response, or view on the CloudFormation console. Ex, you can output the S3 bucket name for a stack to make the bucket easier to find.
- Mappings
- The optional Mappings section matches a key to a corresponding set of named values. Ex, if you want to set values based on a region, you can create a mapping that uses the region name as a key and contains the values you want to specify for each specific region.
- Rules
- The optional Rules section validates a parameter or a combination of parameters passed to a template during a stack update.
- Resources
Elastic Beanstalk
- Choose a platform, upload your code and it runs with little worry for developers about infrastructure knowledge
- No recommended for Production application
- Elastic Beanstalk is powered by a CloudFormation template setups for you
- ELB
- ASG
- RDS
- EC2 platforms
- Monitoring (CloudWatch, SNS)
- In-Place and Blue/Green elopement methodologies
- Security
- Can run Dockerized environments
- Beanstalk is free, but you pay the underlying infrastructure
- Enviroemnt Tier
- Web-Server Tier
- Serves HTTP requests
- Worker Tier
- Pulls tasks from an SQS queue
- Web-Server Tier
- Environment Types
- Load-balanced, scalable environemnt
- ELB + ASG + EC2
- Single-instance environment
- EC2 + Elastic IP
- Load-balanced, scalable environemnt
- Elastic Beanstalk component can create Web Server environments and Worker environments
- The worker environments in Elastic Beanstalk include an ASG and an SQS queue.
- It is not used for serverless applications.
- Terraform is an open-source infrastructure as code software tool to configure the infrastructure.
- Elastic Beanstalk supports the deployment of web applications from Docker containers. With Docker containers, you can define your own runtime environment. You can choose your own platform, programming language, and application dependencies that aren’t supported by other platforms.
- Note: Deploying Docker containers using CloudFormation is not an ideal choice.
- Elastic Beanstalk is an easy-to-use serivce for deploying and scaling web applications and services.
- We can retain full control over the AWS resources used in the application and access the underlying resources at any time
- Elastic Beanstalk vs ECS
- With ECS, you’ll have to build the infrastructure first before you can start deploying the Dockerfile
- With Elastic Beanstalk, you provide a Dockerfile, and Elastic Beanstalk takes care of scaling your provisioning of the number and size of nodes.
- Elastic Beanstalk vs CloudFormtaion
- Elastic Beanstalk is intended to make developers’ lives easier
- CloudFormation is intended to make systems engineers’ lives easier
- CloudFormation doesn’t automatically do anything.
Cognito
- Cognito User Pools (CUP)
- Sign in / Sign up functionality for app users
- Integrate with API Gateway
- Create a serverless database of user for your mobile apps
- Simple login: Username (or email) / password combination
- Possibility to verify emails / phone numbers and add MFA
- Can enable Federated Identity (Facebook, Google, SAML, ….)
- Sends back a JSON Web Token (JWT)
- CUP is a IdP
- Cognito Identity Pools (Federated Identity)
- Provide AWS credentials to users so they can access resources directly
- Integrate with User Pools as an identity provider
- get temporary AWS credentials back from the Federated Identity Pool
- These credentials come with a pre-defined IAM policy stating their permissions
- Cognito Sync
- Synchronize data fromm device to Cognito
- Maybe deprecated and replaced by AppSync
- Store preferences, configuration, state of app
- Cross device synchronization
- Requires Federated Identity Pool in Cognito (not User Pool)
- SAML: A type of Identity Provider which is used for SSO
- OIDC: A type of Identity Provider which uses OAuth
- tech of IdP
- SAML
- SSO
- OAuth
- OpenID
- Federated identity providers are used to authenticate users. Then the Cognito identity pool provides the temporary token that authorizes users to access AWS resources.
- Identity Providers authenticate users, not authenticate services.
- Cognito supports both authenticated and unauthenticated users.
- Cognito supports more than just social identity providers, including OIDC, SAML, and its own identity pools.
ECS
- Features of ECS
- Containers and Images
- Task Definitions
- Tasks and Scheduling
- Clusters
- Container Agent
- ECS is a container orchestration service
- ECS helps you run Docker containers on EC2 instances
- ECS is ideal for performing batch processing, and it should scale up or down based on the number of messages in the queue.
- ECS is made of
- ECS Core: Running ECS on user-provisioned EC2 instances
- Fargate: Running ECS tasks on AWS provisioned compute (serverless)
- EKS: Running ECS on AWS-powered Kubernetes (running on EC2)
- ECR: Docker Container Registery hosted by AWS
- Use Cases
- Microservices
- Direct integration with ALB
- Auto scaling capability
- Easy service discovery features
- Lambda, ECS, and API Gateway are serverless independent and easily scale up and down
- Run batch processing / scheduled tasks
- Scheduled ECS containers to run On-demand / Reserved / Spot instances
- Migrate application to the cloud
- Dockerize legacy applications running on premises
- Move Docker containers to run on ECS
- Microservices
- ALB Integration
- ALB has a direct integration feature with ECS called “port mapping”
- Use Cases
- Increased resiliency even if running on one EC2 instance
- Maximize utilization of CPU / cores
- Ability to perform rolling upgrades without impacting application uptime
- IAM Task Roles
- The EC2 instances should have an IAM role allowing it to access the ECS service (for the ECS agent)
- An ECS Task is a running Docker container
- ECR is a fully managed Docker container registry that makes it easy for developers to store, manage, and deploy Docker container images
- Service Definition
- defines which task definition to use with your service, how many instantiations of that task to run, and which load balancers associate with your tasks
- Parameters defined in Service Definition
- loadbalancers
- serviceRegistries
- placementConstrains
- networkConfiguration
- cluster
- taskDefinition
- role
- Task Definitions
- To prepare your application to run on ECS, you create a task definition. The task definition is a text file, in JSON format, that describes one or more containers, up to a maximum of ten, that form your application. It can be thought of as a blueprint for your application. Task definitions specify various parameters for your definition.
- Some of parameters you can specify in a task definition
- Docker images
- How much CPU and memory to use with each container
- The launch type to use
- Whether container are linked together in a task
- The Docker networking mode to use for the container in your task
- (Optional) The ports from the container to map to the host container instance
- Whether the task should continue to run if the container finishes or fails
- The command the container should run when it is started
- (Optional) The environment variables that should be passed to the container when it starts
- Any data volumes that should be used with containers in the task
- (Optional) The IAM role that your tasks should use for permissions
- Container Agent
- It runs on each infrastructure resource within an ECS cluster. It sends information about the resource’s current running tasks and resource utilization to ECS, and ECS can send start or stop request to agent.
- Container instances needs a public ID address, VPC Endpoints or a NAT Gateway to communicate with ECS Service
- ECS-optimized AMI looks for agent configuration data in the /etc/ecs/ecs.config file when the container agent starts. You can specify this configuration data at launch with EC2 user data.
- You have root access to the operating system of your container instances
- Container instances must have an IAM role to have sufficient permissions to communicate with ECS
- ex: ecs:Poll, it provides container instance with agent permission to connect with ECS service to report status and get commands
- ecs: CreateCluster, provided that the cluster you intend to register your container instance into already exists. If the cluster does not already exist, the agent must have permission to create it, or you can create the cluster with the create-cluster command prior to launching your container instance.
- ECS Launch Types
- Fargate Launch Type
- ECS Launch Type
- How to use
- Create a docker image of your batch processing application
- Deploy the image as an ECS task
Snowball & Snowball Edge & Snowmobile
Snowball
Petabyte-scale data transfer service
It costs thousands of dollars to transfer 100TB over high speed internet, Snowball can reduce that costs by 1/5th
It can take 100TB over 100 days to transfer over high speed internet, Snowball can reduce that transfer time by less than a week
Data is encrypted end-to-end (256-bit encryption)
Two sizes: 50TB & 80TB
If it takes more than a week to transfer over the network, use Snowball instead
Snowball Edge
Snowball Edge add computational capability to the device
100TB capacity with either
- Storage optimized
- Compute optimized
Supports a custom EC2 AMI so you can perform processing on the go
Supports custom Lambda functions
Very useful to pre-process the data while moving
Use case
- Data migration
- Image collation
- IoT capture
- Machine learning
Two sizes: 100TB & 100TB clustered
Snowmobile
- Transfer 100PB per Snowmobile
- It is a exabyte-scale migration
Redshift
Fully managed Petabyte-size data warehouse
Columnar Store database which can SQL-like queries and is an OLAP
load from
- S3
- EMR
- DynamoDB
- multiple data sources on remote hosts
Redshift can run via a single node or multi-node (clusters)
Pricing
- starts at just $0.25 per hour with no upfront costs or commitments
- scale up to petabytes for $1000 per terabyte per year
- Redshift is price is less than 1/10 cost of most similar services
Configuration
- Single Node
- Nodes come in sizes of 160GB.
- Multi-Node
- You can launch a cluster of nodes with Multi-Node mode
- Leader Node: manages client connections and receiving queries
- Compute Node: stores data and performs queries up to 128 compute nodes
- Single Node
Node Type and Sizes
- Dense Compute (DC): best for high performance, but they have less storage
- Dense Storage (DS): clusters in which you have a lot of data
Compression
- Uses multiple compression techs to achieve significant compression to traditional relational data stores
- Similar data is stored sequentially on disk
- Does not require indexes or materialized view, which saves a lot of space compred to traditional databases
- When loading data to an empty table, data is sampled and the most appropriate compression scheme is selected automatically
Processing
- Redshift uses Massively Parallel Processing (MPP)
- Automatically distributes data and query loads acrosss all nodes
Backups
- Backups are enabled by default with a one day retention period. Retention period can be modified up to 35 days
- maintain at least 3 copies of your data
- The original copy
- Replica on the compute nodes
- Backup copy in S3
- Can asynchronously replicate your snapshots to S3 in a different region
- Manual Snapshot
- By default, manual snapshots are retained indefinitely, even after you delete you cluster. You can specify retention period when you create a manual snapshot or change the retention period by modifying the snapshot. If you create a snapshot using Redshift console, the default retention period is 365 days.
- Automated Snapshot
- Automated snapshots are automatically deleted within the period of 1(Lest) to 35(Max) days.
Database Encryption can be applied using
Redshift uses a hierarchy of encryption keys to encrypt the database. You can use either AWS KMS or a HSM to manage the top-level encryption keys in this hierarchy.
KMS multi-tenant HSM
CloudHSM single-tenant HSM
Avaialbility
- Redshift is Single-AZ
- To run in multi-AZ you would have to run multiple Redshift Cluster in different AZs with the same inputs
- Snapshots can be restored to a different AZ in the event an outage occurs
Database Encryption
- KMS multi-tenant HSM
- CloudHSM single-tenant HSM
Redshift Enhanced VPC Routing
- It provides VPC resources access to Redshift.
- Without it, Redshift cannot be able to access the S3 VPC endpoints.
- Without it, NAT instance cannot be reached by Redshift.
Cross-Region Snapshots
- Snapshots are available for Redshift clusters enabling them to be available in different regions
If you intend to keep your Redshift cluster running continuously for a prolonged period, you should consider purchasing reserved node offerings. But you need to pay for those nodes for either one-year or three-year duration.
ElastiCache
- Managed caching service which either runs Redis or Memcached
- Helps make your application stateless
- Write Scaling using sharding
- Read Scaling using Read Replicas
- Multi AZ with Failover Capability
- ElastiCache - Redis vs Memcached
- Redis
- Multi AZ with Auto-Failover
- Read Replicas to scale reads and have HA
- Data Durability using Append Only File (AOF) persistence
- Backup and restore features
- It’s very good for leaderboards, keep track of unread notification data. It’s very fast, but arguably not as fast as Memcached
- Memcached
- Multi-node for partitioning of data (sharding)
- Non persistent
- No backup and restore
- Multi-threaded architecture
- Memcached is generally preferred for caching HTML fragments.
- Redis
- IAM policies on ElastiCache are only used for AWS API-level security
- Redis AUTH
- You can set a “password/token” when you create a Redis cluster
- This is an extra level of security for your cache (on top of SG)
- To use Redis AUTH that will require users to provide a password before accessing Redis Cluster, in-transit encryption needs to be enabled on the cluster while creating the cluster.
- For Redis AUTH, clusters must enabled with in-transit encryption during initial deployment, not at-rest encryption.
- Memcached supports SASL-based authentication (advanced)
- Patterns for ElastiCache
- Lazy Loading: all the read data is cached, data can become state in cache
- Write Through: Adds or update data in the cache when written to a DB (no stale data)
- Session Store: store temporary session data in a cache (using TTL features)
- Quote: There are only two hard things in CS
- Cache Invalidation
- Naming
- ElastiCache is only accessible to resource operating with the same VPC to ensure low latency
Kinesis
- Kinesis is a managed alternative to Apache Kafka
- Great for application logs, metrics, IoT, clickstreams
- Great for “real-time” big data
- Data is automatically replicated to 3 AZs
- Components of Kinesis
- Kinesis Streams: low latency streaming ingest at scale
- Kinesis Analytics: perform real-time analytics on streams using SQL
- Kinesis Firehose: load streams into S3, Redshift, ElasticSearch…
- Kinesis Streams
- Streams are divided in ordered Shards / Partitions
- Data retention is 1 day by default, can go up 7 days
- Ability to reprocess / replay data
- Multiple applications can consume the same stream
- Real-time processing with scale of throughput because of shards
- Once data is inserted in Kinesis, it can’t bee deleted (immutability)
- You pay per running shard
- It is an ordered sequence of data records
- stores the records from 24h up to 168h
- Kinesis Streams Shards
- One stream is made of many different shards
- 1 MB/s or 1000 messages/s at write PER SHARD
- 2 MB/s at read PER SHARD
- Billing is per shard provisioned, can have as many shards as you want
- Batching available or per message calls
- The number of shards can evolve over time (reshard / merge)
- Records are ordered per shard
- Kinesis API
- Put Records
- PutRecord API + Partition key that gets hashed
- The same key goes to the same partition
- Messages sent get a “sequence number”
- Use Batching with PutRecords to reduce costs and increase throughput
- ProvisionedThroughputExceeded if we go over the limits
- Can use CLI, AWS SDK, or producer libraries from various frameworks
- Exceptions
- ProvisionedThroughputExceeded Exceptions
- Happens when sending more data (exceeding MB/s or TPS for any shard)
- Make sure you don’t have a lot shard (such as your partition key is bad and too much data goes to that partition)
- Solution
- Retries with backoff
- Increase shards(scaling)
- Ensure your partition key is good one
- ProvisionedThroughputExceeded Exceptions
- Customers
- Can use a normal consumer (CLI, SDK, etc…)
- Can use Kinesis Client Library (in Java, Node, Python, Ruby, .Net)
- KCL uses DynamoDB to checkpoint offsets
- KCL uses DynamoDB to track other workers and share the work amongst shards
- Put Records
- Kinesis Data Firehose
- Fully Managed Service, no administration, automatic scaling, serverless
- Load data into
- Redshift
- S3
- ElasticSearch
- Splunk
- Near Real Time
- 60 seconds latency minimum for non full batches
- Or minimum 32 MB of data at a time
- Supports many data formats, conversions, transformations, compression
- Pay for the amount of data going through Firehose
- Data immediatelly disappears once it’s consumed
- You pay only for data that is ingested
- Kinesis Data Streams vs Firehose
- Streams
- Going to write custom code (producer / consumer)
- Real time (~200ms)
- Must manage scaling (shard splitting / merging)
- Data Storage for 1 to 7 days, replay capability, multi consumers
- Firehose
- Serverless data transformation with Lambda
- Near real time (lowest buffer time is 1 minute)
- Automated Scaling
- No data storage
- Streams
- Kinesis Analytics
- Perform real-time analytics on Kinesis Streams using SQL
- Kinesis Data Analytics
- Auto Scaling
- Managed: no servers to provision
- Continuous: real time
- You can specify Firehose or Data Streams as an input and an output
- Ordering data into SQS
- For SQS FIFO, if you don’t use Group ID, messages are consumed in the order they are sent, with only one consumer
- You want to scale the number of consumers, but you want messages to be “grouped” when they are realted to each other, then use Group ID (similar to Partition Key in Kinesis)
- Kinesis Data Streams vs SQS FIFO
- Data Streams
- data will be ordered within each shard
- The maximum amount of consumers in parallel we can have is 5
- Can receive up to 5 MB/s of data
- SQS FIFO
- You only have one SQS FIFO queue
- You will have 100 Group ID
- You can have up to 100 consumers (due to the 100 Group ID)
- You have up to 300 messages per second (or 3000 if using batching)
- Data Streams
- Kinesis Video Analytics
- Output video data to ML or video processing services
EMR
- EMR stands for Elastic MapReduce
- EMR helps creating Hadoop clusters (Big Data) to analyze and process vast amount of data
- Not for a data streaming service
- The clusters can be made of hundreds of EC2 instances
- Also supports Apache Spark, HBase, Presto, Flink…
- EMR takes care of all the provisioning and configuration
- Auto-scaling and integrated with Spot instances
- Use cases: data processing, ML, web indexing, big data…
Glue
- Fully managed ETL (Extract, Transform & Load) service
- Automating time consuming steps of data preparation for analytics
- Serverless, provisions Apache Spark
- Crawl data sources and identifies data formats (schema interface)
- Automated Code Generation
- Sources
- Aurora
- RDS
- Redshift
- S3
- Sinks
- S3
- Redshift
- Glue Data Catalog: Metadata (definition & schema) of the Source Tables
- the table in Glue is used to define the data schema.
- Crawler
- Performing ETL jobs
- Classifier
- Generating a schema
Amazon MQ
- Amazon MQ = managed Aapche Active MQ
- Amazon MQ doesn’t “scale” as much as SQS/SNS
- Amazon MQ runs on a dedicated machine, can run in HA with failover
- Amazon MQ both has queue feature (SQS) and topic feature (SNS)
SQS vs SNS vs Kinesis
SQS
- Consumer pull data
- Data is deleted after being consumed
- Can have as many consumers as we want
- No need to provision throughput
- No ordering guarantee (except FIFO features)
- Individual message delay capability
SNS
- Push data to many subscribers
- Up to 10,000,000 subscribers
- Data is not persisted (lost if not delivered)
- Pub/Sub
- Up to 100,000 topics
- No need to provision throughput
- Integrates with SQS for fan-out architecture pattern
Kinesis
- Consumers pull data
- As many consumers as we want
- Possibility to replay data
- Meant for real-time big data, analytics and ETL
- Ordering at the shard level
- Data expires after X days
- Must provision throughput
Resource Groups (same with Application Manager)
- Create, view or manage logical group of resources thanks to tags
- Allows creation of logical groups of resources
- Applications
- Different layers of an application stack
- Production vs development environments
- Regional service
- Works with EC2, S3, DynamoDB, Lambda
- Group Type
- Tag based
- CloudFormation stack based
Resource Groups - Tags
- Free naming, common tags are
- Name
- Environment
- Team
- Used for
- Resources grouping
- Automation
- Cost allocati
- Better to have too many tags than too few
- You can easily add tags to define which instances are the production instances and which ones are development instances. These tags can be used while controlling access via an IAM policy
Resource Access Manager (RAM)
- Share AWS resources that you own with other AWS accounts
- Share with any account or within your organization
- Avoid resource duplication
- Share
- VPC Subnets
- Allow to have all the resources launched in the same subnets
- must be from the same AWS Organization
- Cannot share SG and default VPC
- Participants can manage their own resources in there
- Participants can’t view, modify, delete resources that belong to other participants or the owner
- Share VPC, but not resources among it
- AWS Transit Gateway
- Route 53 Resolver Rules
- License Manager Configuration
- VPC Subnets
- In RAM, you should directly share the resource to the AWS Organization rather than all the AWS accounts in RAM
Storage Gateway
- Hybrid Cloud for Storage
- AWS Storage Cloud Native Options
- Block
- EBS
- EC2 Instance Store
- File
- EFS
- Object
- S3
- Glacier
- Block
- It’s a bridge between on-premise data and cloud data in S3
- Use case: DR, backup & restore, tiered storage
- 3 types of Gateway
- File Gateway (NFS)
- store your files in S3
- Access your files through a NFS or SMB mount point
- Supports S3 standard, S3 IA, S3 One Zone IA
- Bucket access using IAM roles for each File Gateway
- Most recently used data is cached in the file gateway
- Can be mounted on many servers
- Once a file is transferred to S3, it can be managed as a native S3 object
- Bucket Policies, Versioning, Lifecycle Management, and CRR apply directly to objects stored in your bucket
- Volume Gateway (iSCSI)
- Volume Gateway presents your applications with disk volumes usingn the Internet Small Computer System Interface (iSCSI) block protocol
- Data that is written to volumes can be asynchronously backed up as point-in-time snapshots of the volumes, and stored in the cloud as AWS EBS Snapshots
- All snapshots storage is also compressed to help minimize your storage charges
- store copies of your hard disk drives in S3
- store as EBS
- Stored Volumes
- Primary data is stored locally, while asychronously backing up that data to AWS
- Provide your on-premises application with low-latency access to their entire datasets, while still providing durable off-site backups
- Stored Volumes can be between 1GB - 16TB in size
- Cached Volumes
- Low latency access to most recent data
- Let you use S3 as your primary data storage, while retaining frequently accessed data locally in your data storage
- Minimize the need to scale your on-premises storage infrastructure, while still providing your applications with low latency data access
- Create storage volumes up to 32TB in size and attach them as iSCSI devices from your on-premises servers
- Tape Gateway (VTL)
- Backups virtual tapes to S3 Glacier for long archive storage
- A durable, cost-effective solution to archive your data in the AWS Cloud
- Supported by NetBackup, Backup Exec, and Veeam
- File Gateway (NFS)
- All three storage gateway patterns are backed by S3
- On-premises data to the cloud => Storage Gateway
- File access / NFS => File Gateway (backed by S3)
- Volumes / Block Storage / iSCSI => Volume Gateway (backed by S3 with EBS snapshots)
- VTL Tape solution / Backup with iSCSI => Tape Gateway (backed by S3 and Glacier)
FSx
Amazon FSx for Windows (File Server)
- EFS is shared POSIX system for Linux systems, FSx for Windows is not POSIX-compliant file system
- POSIX stands for Portable Operating System Interface
- FSx for Windows is a fully managed Windows file system share drive
- Supports SMB protocol & Windows NTFS
- Microsoft Active Directory integration, ACLs, user quotas
- Built on SSD, scale up to 10s of GB/s, millions of IOPS, 100s PB of data
- Can be accessed from your on-premise infrastructure
- Can be configured to be Multi-AZ (HA)
- Data is backed-up daily to S3
- for enterprise workloads
- FSx for Windows File Server supports across VPCs, accounts, and Regions via Direct Connect or VPN (on-premises) and VPC Peering or AWS Transit Gateway
Amazon FSx for Lustre
FSx for Lustre is a POSIX-compliant file server.
Lustre is a type of parallel distributed file system, for large-scale computing
The name Lustre is derived from “Linux” andn “Cluster”
ML, HPC, Video Processing, Financial Modeling, Electronic Design Automation
Scales up to 100s GB/s, millions of IOPS, sub-ms latencies
Seamless integration with S3
- Can “read S3” as a file system (through FSx)
- Can write the output of the computations back to S3 (through FSx)
Can be used from on-premises servers
for high-performance workloads
Storage Comparison
- S3: Object Storage
- Glacier: Object Archival
- EFS: Network File System for Linux instances, POSIX file system
- FSx for Windows: Network File System for Windows servers
- FSx for Lustre: High Performance Computing Linux file system
- EBS volumes: Network storage for one EC2 instance at a time
- Instance Storage: Physical storage for your EC2 instance (high IOPS)
- Storage Gateway: File Gateway, Volume Gateway (cached & stored), Tape Gateway
- Snowball / Snowmobile: to move large amount of data to the cloud, physically
- Database: for specific workloads, usually with indexing and querying
Database Comparison
Database Types
- RDBMS (=SQL/OLTP): RDS, Aurora - great for joins
- NoSQL database: DynamoDB (~JSON), ElastiCache (key/value pairs), Neptune (graphs) - no joins, no SQL
- Object Store: S3 (for big objects) / Glacier (for backups / archives)
- Data Warehouse (=SQL Analytics / BI): Redshift (OLAP), Athena
- Search: ElasticSearch (JSON) - free text, unstructured searches
- Graphs: Neptune - displays relationships between data
RDS
- Must provision an EC2 instance & EBS Volume type and size
- Support for Read Replicas and Multi AZ
- Security through IAM, SG, KMS, SSL in transit
- Backup / Snapshot / Point in time restore feature
- Managed and Scheduled maintenance
- Monitoring through CloudWatch
- Operations: small downtime when failover happens, when maintenance happens, scaling in read replicas / ec2 instance / restore EBS implies manual intervention, application changes
- Security: KMS, SG, IAM policies, SSL in transit
- Reliability: Multi AZ, failover in case of failures
- Performance: depends on EC2 instance type, EBS volume type, ability to add Read Replicas, doesn’t auto-scale
- Cost: Pay per hour based on provisioned EC2 and EBS
Aurora
- Data is held in 6 replicas, across 3 AZ
- Auto healing capability
- Multi AZ, Auto Scaling Read Replicas
- Read Replicas can be Global
- Aurora database can be Global for DR or latency purposes
- Auto scaling of storage from 10GB to 64TB
- Define EC2 instance type for aurora instances
- Aurora Serverless option
- Operations: less operation, auto scaling storage
- Security: same with RDS
- Reliability: Multi AZ, highly available, possibly more than RDS, Aurora Serverless option
- Performance: 5x performance due to architectural optimizations. Up to 15 Read Replicas (only 5 for RDS)
- Cost: Pay per hour based on EC2 and storage usage. Possibly lower costs compared to Enterprise grade databases sucha as Oracle
ElastiCache
- Managed Redis / Memcached
- In-memory data store, sub-millionsecond latency
- Must provision an EC2 instance type
- Support for Clustering (Redis) and Multi AZ, Read Replicas (sharding)
- Security through IAM, SG, KMS, Redis Auth
- Backup / Snapshot / Point in time restore feature
- Managed and Scheduled maintenance
- Monitoring through CloudWatch
- Operations: same as RDS
- Security: same with RDS, but can also use Redis Auth
- Reliability: Clustering, Multi AZ
- Performance: Sub-millisecond performance, in memory, read replicas for sharing, very popular cache option
- Cost: Pay per hour based on EC2 and storage usage
DynamoDB
- NoSQL database
- Serverless, provisioned capability, auto scaling, on demand capability
- Can replace ElastiCache as a key/value store (storing session data for example)
- HA, Multi AZ by default, Read and Writes are decoupled, DAX (DynamoDB Accelerator) for read cache
- Reads can be eventually consistent or strongly consistent
- DynamoDB Streams to integrate with AWS Lambda
- Backup/Restore feature, Global Table feature
- Monitoring through CloudWatch
- Can only query on primary key, sort key, or indexes
- Operations: no operations needed, auto scaling capability, serverless
- Security: full security through IAM policies, KMS encryption, SSL in flight
- Reliability: Multi AZ, Backups
- Performance: single digit millisecond performance, DAX for caching reads, performance doesn’t degrade if your application scales
- Cost: Pay per provisioned capability and storage usage (no need to guess in advance any capacity - can use auto scaling)
S3
- Great for big objects
- Serverless, scales infinitely, max object size is 5TB
- Eventually consistency for overwrites and deletes
- Tiers: S3 Standard, S3 IA, S3 One Zone IA, Glacier for backups
- Features: Versioning, Encryption, CRR
- Encryption: SSE-S3, SSE-KMS, SSE-C, client side encryption, SSL in transit
- Operations: no operation needed
- Security: IAM, Bucket Policies, ACL, Encryption, SSL
- Reliability, 11 9’s durability and 4 9’s availability, Multi AZ, CRR
- Performance: scales to thousands of reads/writes per second, transfer acceleration / multipart for big files
- Cost: pay per storage usage, network cost, requests number
Athena
- Fully Serverless database with SQL capabilities
- Used to query data in S3
- Pay per query
- Output results back to S3
- Secured through IAM
- Operations: no operations needed, serverless
- Security: IAM + S3 security
- Reliability: mannaged service, uses Presto engine, highly available
- Performance: queries scale based on data size
- Cost: pay per query / per TB of data scanned, serverless
Redshift
- Redshift is based on PosgreSQL, but it’s not used for OLTP, it’s OLAP
- 10x better performance than other data warehouses, scale to PBs of data
- Columnar storage of data
- MPP, highly available
- Pay as you go based on the instances provisioned
- Has a SQL interface for performing the queries
- BI tools such as AWS Quicksight or Tableau integrate with it
- From 1 node to 128 nodes, up to 160GB of space per node
- Two type of nodes
- Leader Node: for query planning, results aggregation
- Compute Node: for performing the queries, send results to leader
- Redshift Spectrum: perform queries directly against S3 (no need to load)
- Backup & Restore, Security VPC / IAM / KMS, Monitoring
- Redshift Enhanced VPC Routing: COPY / UNLOAD goes through VPC
- Redshift - Snapshots & DR
- Snapshots are point-in-time backups of a cluster, stored internally in S3
- Snapshots are incremental (only what has changed is saved)
- You can restore a snapshots into a new cluster
- Automated: every 8 hours, every 5 GB, or on a schedule. set retention
- Manual: snapshot is retained untile you delete it
- You can configure Amazon Redshift to automatically copy snapshots of a cluster to another AWS region
- Redshift Spectrum
- Query data that is already in S3 without loading it
- Must have a Redshift cluster available to start the query
- The query is then submitted to thousands of Redshift Spectrum nodes
- Operations: similar to RDS
- Security: IAM, VPC, KMS, SSL
- Reliability: highly available, auto healing features
- Performance: 10x performance vs other data warehousing, compression
- Cost: pay per node provisioned, 1/10th of the cost vs other warehouses
- Remember: Redshift = Analytics / BI / Data Warehouse
Neptune
- fully managed graph database
- When do we use Graph?
- High relationship data
- Social Networking
- Knowledge graphs
- High available across 3 AZ, with up to 15 read replicas
- Point-in-time recovery, continuous backup to S3
- Support for KMS encryption at rest + HTTPS
- Operations: similar to RDS
- Security: IAM, VPC, KMS, SSL + IAM Authentication
- Reliability: Multi AZ, clustering
- Performance: best suited for graphs, clustering to improve performance
- Cost: pay per node provisioned
- Remember: Neptune = Graphs
ElasticSearch
- Search any field, even partially matches
- It’s common to use ElasticSearch as a complement to another database
- You can provision a cluster of instances
- Built-in integrations: Amazon Kinesis Data Firehose, AWS IoT, and Amazon CloudWatch Logs for data ingestion
- Comes with ELK stack
- Operations: similar to RDS
- Security: Cognito, IAM, VPC, KMS, SSL
- Reliability: Multi AZ, clustering
- Performance: based on ElasticSearch project, petabyte scale
- Cost: pay per node provisioned
- Remember: ElasticSearch = Search / Indexing
Config
- Helps with auditing and recording compliance of your AWS resources
- Helps record configurations and changes over time
- Possibility of storing the configuration data in S3 (analyzed by Athena)
- Questions that can be solved by AWS Config
- Is there unrestricted SSH access to my SG?
- Do my buckets have any public access?
- How has my ALB configuration changed over time?
- You can receive alerts for any changes
- AWS Config is a region service
- Can be aggregated across regions and accounts
- AWS Config Resource
- View compliance of a resource over time
- View configuration of a resource over time
- View CloudTrail API calls if enabled
- AWS Config Rules
- Can use AWS managed config rules
- Can make custom config rules (must be defined in AWS Lambda)
- Evaluate if each EBS disk is of type gp2
- Evaluate if each EC2 instance is t2.micro
- Rules can be evaluated / triggered
- For each config change
- And / Or: at regular time intervals
- Can trigger CloudWatch Events if the rule is non-compliant (and chain with Lambda)
- Rules can have auto remediations
- If a resource is not compliant, you can trigger an auto remediation
- Ex: stop instances with non-approved tags
- AWS Config Rules does not prevent actions from happening (no deny)
- Pricing: no free tier, $2 per active rule per region per month
CloudWatch vs CloudTrail vs Config
CloudWatch
- Performance monitoring (metrics, CPU, network, etc…) & dashboards
- Events & Alerting
- Log Aggregation & Analysis
CloudTrail
- Record API calls made within your Account by everyone
- Can define trails for specific resources
- Global Service
Config
- Record configuration changes
- Evaluate resources against compliance rules
- Get timeline of changes and compliance
ex: For an ELB
- CloudWatch
- Monitoring incoming connection metric
- Visulize error codes as a % over time
- Make a dashboard to get an idea of your load balancer performance
- Config
- Track SG rules for the LB
- Track configuration changes for the LB
- Ensure an SSL certificate is always assigned to the LB (compliance)
- CloudTrail
- Tack who made any changes to the LB with API calls
SSM - Parameter Store
- Secure storage for configuration and secrets
- Optional Seamless Encryption using KMS
- Serverless, scalable, durable, easy SDK
- Version tracking of configuration / secrets
- Configuration management using path & IAM
- Notification with CloudWatch Events
- Integration with CloudFormation
- Parameter Policies (only for advanced parameters)
- Allow to assign a TTL to a parameter (expiration date) to force updating or deleting sensitive data such as password
- Can assign multiple policies at a time
- Using CLI/SDK or Lambda to require a parameter from Parameter Store
Secrets Manager
- Newer service, meant for storing secrets
- Capability to force rotation of secrets every X days
- Automate generation of secrets on rotation (use Lambda)
- Integration with Amazon RDS (MySQL, PostgreSQL, Aurora)
- supports the key rotation for database credentials, third-party services, etc.
- Natively knows how to rotate secrets for supported databases such as RDS. For other secret types, such as API keys, users need to cutomize the Lambda rotation function.
- Secrets are encrypted using KMS
- Mostly meant for RDS integration
- In each application, only one secret in Secrets Manager is required, and the application should always get the latest version of the secret.
- there is no configuration to enable rotation for all secrets. The rotation is managed in each secret.
- CloudWatch must use Lambda function to check if rotation is enabled
- AWS Config rule “secretsmanager-rotation-enabled-check” checks whether AWS Secrets Manager secret has rotation enabled. Users need to add the rule in AWS Config and set up a notification.
CloudHSM
- KMS = AWS manages the software for encryption
- CloudHSM = AWS provisions encryption hardware
- Dedicated Hardware (HSM = Hardware Security Module)
- You manage your own encryption keys entirely (not AWS)
- HSM device is tamper resistant
- CloudHSM clusters are spread across Multi AZ (HA) - must setup
- Supports both symmetric and asymmetric encryption (SSL/TLS keys)
- No free tier available
- Must use the CloudHSM Client Software
- Redshift supports CloudHSM for database encryption and key management
- Good option to use with SSE-C encryption
- CloudHSM Software is not within the AWS console
- Backup
- To back up the CloudHSM data to S3 buckets in the same region, CloudHSM generates a unique Ephemeral Backup Key (EBK) to encrypt all data using AES 256-bit encryption key. This Ephemeral Backup Key is further encrypted using Persistent Backup Key (PBK), which is also an AES 256-bit encryption key.
- backup CloudHSM data -> using EBK encrypt data -> using PBK encrypt EBK key
Shield
- It is a service to protect web applications against DDoS attacks
AWS Shield Standard
- Free service that is activated for every AWS customer
- Provides protection from attacks such as SYN/UDP Floods, Reflection attacks and other layer 3 / layer 4 attacks
AWS Shield Advanced
- Optional DDoS mitigation service ($3,000 per month per organization)
- Protect against more sophisticated attack on Amazon EC2, ELB, CloudFront, Global Accelerator, and Route 53
- 24/7 access to AWS DDoS response team (DRP)
- Protect against higher fees during usage spikes due to DDoS
WAF
- WAF stands for Web Application Firewall
- Protect your web application from common web exploits (Layer 7)
- Deploy on ALB, API Gateway, CloudFront
- Define Web ACL (Web Access Control List)
- Rules can include: IP, HTTP header, HTTP body, or URI strings
- Protects from common attack - SQL injection and Cross-Site Scripting (XSS)
- Size constraints, geo-match (block countries)
- Rate-based rules (to count occurrences of events) - for DDoS protection
- AWS Firewall Manager
- Manage rules in all accounts of an AWS Organization
- Common set of security rules
- WAF rules (ALB, API Gateways, CloudFront)
- AWS Shield Advanced (ALB, CLB, Elastic IP, CloudFront)
- SG for EC2 and ENI resources in VPC
- AWS provides the PHP protection rule in WAF. Users can add the rule in Web ACL.
Encryption
- Encryption in flight (SSL)
- SSL certificates help with encryption (HTTPS)
- Encryption in flight ensures no MITM (man in the middle attack)
- Server side encryption at rest
- Client side encryption
- Data is encrypted by the client and never decrypted by the server
- Data will be decrypted by a receiving client
- The server should not be able to decrypt the data
- Could leverage Envelope Encryption
STS
STS stands for Security Token Service
Allows you to grant limited and temporary access to AWS resources
Token is valid for up to one hour (must be refreshed)
APIs
AssumeRole
- Within your own account: for enhanced security
- Cross Account Access: assume role in target account to perform actions there
AssumeRoleWithSAML
- return credentials for users logged with SAML
AssumeRoleWithWebIdentity
- return credentials for users logged with an IdP (Facebook Login, Google Login, OIDC compatible…)
GetFederationToken
- For IAM user or AWS account root user
- the permission of GetFederationToken
- AWS allows the federated user’s request only when both the attacheed policy and the IAM user policy explicitly allow the federated user to perform the requested action.
- You can generated FederatedUser credentials using an IAM User, not using an IAM Role
- You must call the GetFederationToken operation using the long-term security credentials of an IAM user.
GetSessionToken
- for MFA, from a user or AWS account root user
Using STS to Assume a Role
- Define an IAM Role within your account or cross-account
- Define which principals can access this IAM Role
- User AWS STS to retrieve credentials and impersonate the IAM Role you have access to (AssumeRole API)
- Temporary credentials can be valid between 15 minutes to 1 hour
Identity Federation in AWS
- Federation lets users outside of AWS to assume temporary role for accessing AWS resources
- These users assume identity provided access role
- Federation can have many flavors
- SAML 2.0
- To integrate Active Directory / ADFS with AWS (or any SAML 2.0)
- Provides access to AWS Console or CLI (through temporary credentials)
- No need to create an IAM user for each of your employees
- Needs to setup a trust between AWS IAM and SAML (both ways)
- SAML 2.0 enables web-based, cross domain SSO
- Uses the STS API: AssumeRoleWithSAML
- Note federation through SAML is the “old way” of doing things
- Amazon SSO Federation is the new managed and simpler way
- Custom Identity Broker
- Use only identity provider is not compatible with SAML 2.0
- The identity broker must determine the appropriate IAM policy
- Uses STS API: AssumeRole or GetFederationToken
- Not our application talks with STS, but the IdP does
- Web Identity Federation with Cognito
- Goal
- Provide direct access to AWS Resources from the Client Side (mobile, web app)
- Example
- Provide temporary access to write to S3 bucket using Facebook Login
- Problem
- We don’t want to create IAM users for our app users
- How
- Log into federation identity provider - or remain anonymous
- Get temporary AWS credential back from the Federation Identity Pool
- These credentials come with pre-defined IAM Policy stating their permissions
- Goal
- Web Identity Federation without Cognito
- Using AssumeRoleWithWebIdentity
- Not recommended by AWS - use Cognito instead (allows for anonymous users, data synchronization, MFA)
- SSO
- Non-SAML with AWS Microsoft AD
- Found on any Windows Server with AD Domain Service
- Database of objects: User Accounts, Computers, Printer, File Shares, Security Groups
- Centralized security management, create account, assign permissions
- Objects are organized in trees
- A group of trees is a forest
- AWS Directory Services
- SAML 2.0
- Using federation, you don’t need to create IAM users
Directory Service
- It enables your end-users to use their existing corporate credentials while accessing AWS applications. Once you’ve been able to consolidate services to AWS, you won’t have to create new credentials. Instead, you’ll be able to allow the users to use their existing username/password.
- for users who wants to use existing Microsoft AD or LDAP-aware applications in the cloud.
- It can also be used to support Linux workloads that need LDAP service.
- A way to create AD on AWS
- 3 types
- AWS Managed Microsoft AD
- Create your own AD in AWS, manage users locally, supports MFA
- Establish “trust” connection with your on-premise AD
- it can be used for both cloud and on-premises environments (must implement VPN or Direct Connect)
- AD Connector
- Directory Gateway (proxy) to redirect to on-premise AD
- Users are managed on the on-premise AD
- Simple AD
- AD-compatible managed directory on AWS
- Cannot be joined with on-premise AD
- don’t have on-premise AD stuff
- AWS Managed Microsoft AD
- LDAP
- LDAP (Lightweight Directory Access Protocol) is an open and cross platform protocol used for directory services authentication.
- LDAP vs Active Directory
- LDAP is a protocol that many different directory services and access management solutions can understand.
- Active Directory is a directory server that uses the LDAP protocol
Single Sign On Servicee (SSO)
- Centrally manage Single Sign-On to access multiple accounts and 3rd-party business application
- Integrated with AWS Organizations
- Supports SAML 2.0 markup
- Integration with on-premise Active Directory
- Centralized permission management
- Centralized auditing with CloudTrail
- AWS SSO provides login portal
- SSO vs AssumeRoleWithSAML
- AssumeRoleWithSAML
- You need to create a portal site integrated with Identity Store
- You need to connect to STS for requiring token
- SSO
- You don’t need to create a portal site that already exists in SSO
- You don’t need to connect to STS for requiring token
- AssumeRoleWithSAML
Data Migration Service (DMS)
- Quickly and securely migrate databases to AWS, resilient, self healing
- The source database remains available during the migration
- Supports
- Homogeneous migration: Oracle to Oracle
- Heterogeneous migration: Microsoft SQL Server to Aurora
- Continuous Data Replication usingn CDC
- You must create an EC2 instance to perform the replication tasks
- DMS Sources and Targets
- Sources
- On-premise and EC2 instance databases
- Azure
- Amazon RDS
- Amazon S3
- Targetes
- On-premise and EC2 instance databases
- Amazon RDS
- Amazon Redshift
- Amazon DynamoDB
- Amazon S3
- ElasticSearch
- Kinesis Data Streams
- DocumentDB
- Sources
- Schema Conversion Tool & Engine Conversion Tool
- Schema Conversion Tool (SCT)
- For heterogenous conversion
- Convert your database’s schema from one engine to another
- You don’t need to use SCT if you are migrating the same DB engine
- Engine Conversion Tool
- For homogenous database migration
- Schema Conversion Tool (SCT)
DataSync
- Move large amount of data from on-premise to AWS
- Can synchroninze to: S3, EFS, FSx for Windows
- It is not supported FSx for Lustre
- Move data from your NAS or file system via NFS or SMB
- Replication tasks can be scheduled hourly, daily, weekly
- Leverage the DataSync agent to connect to your system
- Transferring a constantly changing dataset between on-premise servers & EFS using AWS DataSync, you could initially uncheck Enable verification, because files at the source are slightly different from files at the destination. You can enable the verification during the final cut-over from on-premises to AWS
AppSync
- Store and sync data across mobile and web apps in real-time
- Makes use of GraphQL (mobile technology from Facebook)
- Client Code can be generated automatically
- Integrations with DynamoDB / Lambda
- Real-time subscriptions
- Offline data synchronization (replaces Cognito Sync)
- Fine Grained Security
Transferring large amount of data into AWS
Example: transfer 200TB of data in the cloud. We have a 100Mbps internet connection.
- Over the internet / Site-to-Site VPN
- Immediate to setup
- Will take 200(TB)*1000(GB)*1000(MB)*8(Mb)/100Mbps = 16,000,000s = 185d
- Over Direct Connect 1Gbps
- Long for one-time setup (over one month)
- Will take 200(TB)*1000(GB)*8(Mb)/1 Gbps = 1,600,000s = 18.5d
- Over Snowball
- Will take 2 to 3 snowball in parallel
- Takes about 1 week for the end-to-end transfer
- Can be combined with DMS
- For on-goning replication / transfers: Site-to-Site VPN or DX with DMS or DataSync
AWS SAM
- SAM = Serverless Application Model
- Framwork for developing and developing serverless applications
- All the configuration is YAML code
- Lambda Functions
- DynamoDB tables
- API Gateway
- Cognito User Pools
- SAM can help you to run Lambda, API Gateway, DynamoDB locally
- SAM can use CodeDeploy to deploy Lambda functions
Step Functions
- Build serverless visual workflow to orchestrate your Lambda functions
- Represent flow as a JSON state machine
- Features: sequence, parallel, conditions, timeouts, error handling
- Can also integrate with EC2, ECS, On premise servers, API Gateway
- Maximum execution time of 1 year
- Possibility to implement human approval feature
- Use Case
- Order fullfillment
- Data processing
- Web applications
- Any workflow
Simple Workflow Service
- Coordinate work amongst applications
- Code runs on EC2 (not serverless)
- 1 year maximum runtime
- Concept of “activity step” and “decision step”
- Has built-in “human intervention” step
- Example: order fulfillment from web to warehouse to delivery
- Step functions is recommended to be used for new applications, except
- If you need external signals to intervene in the processes
- If you need child processes that return values to parent processes
- SWF is older tha Step Functions
Opsworks
- Chef & Puppet help you perform server configuration automatically, or repetitive actions
- They work great with EC2 & On premise VM
- AWS Opsworks = Managed Chef & Puppet
- It’s an alternative to AWS SSM
- In the exam: Chef & Puppet needed => AWS Opsworks
- Quick work on Chef & Puppet
- They help with managing configuration as code
- Helps in having consistent delopyments
- Works with Linus / Windows
- Can automate: user accounts, cron, ntp, packages, services…
- They leverage “Recipes” or “Manifests”
- Chef / Puppet have similarities with SSM / Benstalk / CloudFormation but they’re open-source tools that works cross-cloud
- A stack is basically a collection of instances that are managed together for serving a common task.
Elastic Transcoder
- Convert media files (video + music) stored in S3 into vairous formats for tablets, PC, Smartphone, TV, etc
- Features: bit rate optimization, thumbnail, watermarks, captions, DRM, progressive download, encyption
- 4 components
- Jobs: what does the work of the transcoder
- Pipeline: Queue that manages the transcoding job
- Presets: Template for converting media from one format to another
- Notification: SNS for example
- Pay for what you use, scales automatically, fully managed
WorkSpaces
- Managed, Secure Cloud Desktop
- Great to eliminate management of no-premise VDI (Virtual Desktop Infrasturcture)
- On Demand, pay per by usage
- Secure, Encrypted, Network Isolation
- Integrated with Microsoft Active Directory
WorkMail
- WorkMail is a managed email and calendar service that offers strong security controls and support for existing desktop and mobile clients
WorkDocs
- WorkDocs is a fully managed, secure enterprise storage and sharing service with strong administrative controls and feedback capabilities that improve user productivity.
- Your user’s files are only visible to them, and their designated contributors and viewers. Other members of your organization do not have access to other user’s files unless they are specifically granted access.
- S3 vs WorkDocs
- S3 can’t be used like “Dropbox and Google drive”
- S3 is a bucket storage, not a syncing service
- To restrict all users to invite external users and share WorkDocs links publicly, you can create a Power user responsible for performing this activity.
Organizations
- Global service
- Allows to manage multiple AWS accounts
- The main account is the master account - you can’t change it
- Other accounts are member accounts
- Member accounts can only be part of one organization
- Consolidated Billing across all accounts - single payment method
- Pricing benefits from aggregated usage (volume discount for EC2, S3…)
- API is available to automate AWS account creation
- Multi Account Strategies
- Create accounts per department, per cost center, per dev/test/prod, based on regulatory restrictions (using SCP), for better resource isolation (ex: VPC), to have separate per-account service limits, isolated account for logging
- Multi Account vs One Account Multi VPC
- Multi Account: all resources separate
- One Account Multi VPC: all resources can have chance talk with each other
- Using tagging standard for billing purposes
- Enable CloudTrail on all accounts, send logs to central S3 account
- Establish Cross Account Roles for Admin purposes
- Service Control Policies (SCP)
- Whitelist or blacklist IAM actions
- Applied at the OU or Account level
- Does not apply to the Master Account, but all other accounts, including root accounts of individual accounts in an AWS Organization.
- SCP is applied to all the Users and Roles of the Account, including Root
- The SCP does not affect service-linked roles
- Service-linked roles enable other AWS services to integrate with AWS Organizations and can’t be restricted by SCPs
- SCP must have an explicit Allow (does not allow anything by default)
- Use Case
- Restrict access to certain service (for example: can’t use EMR)
- Enforce PCI compliance by explicit disabling services
- SCP Hierachy
- Account acquire SCP from all its parent OU
- Although one account have a permission for accessing, this account still cannot access the resource since its parent OU denying that
- AWS Organization - Moving Accounts
- To migrate accounts from one organization to another
- Remove the member account from the old organization
- Send an invite to the new organization
- Accept the invite to the new organization from the member account
- If you want the master account of the old organization to also join the new organization, do the following
- Remove all member accounts from the old organization
- Delete the old organization
- Invite the master account of the old organization to be a member account of the new organization
- To migrate accounts from one organization to another
- Resource Sharing
- For accounts that are part of Organization, Resource sharing can be done on an individual account basis if resource sharing is not enabled at the Organization level. With this, resources are shared within accounts as external accounts & an invitation needs to be accepted between these accounts to start resource sharing.
- Avaialble feature sets
- All features
- The default feature set that is available to AWS Organization. It includes all the functionality of consolidated billing, plus advanced features that give you more control over accounts in your organization.
- Consolidated billing
- This feature set provides shared billing functionality, but does not include the more advanced features of AWS Organizations
- All features
- Consolidated Billing
- benefits
- One bill
- Easy tracking
- Combined usage
- You can combine the usage across all accounts in the organization to share the volume pricing discounts
- No extra fee
- benefits
Disaster Recovery
Any event that has a negative impact on a company’s business continuity or finances is a disaster
DR is about perparing for and recovering from a disaster
When we discuss a Disaster Recovery scenario, we assume that the entire region is affected due to the some disaster. We need that service to be provided from another region
Creating an AMI of the EC2 instance and copy it to another region. It’s a Disaster Recovery Solution.
What kind of DR?
- On-premise => On-premise: traditional DR, and very expensive
- On-premise => AWS Cloud: hybrid recovery
- AWS Cloud Region A => AWS Cloud Region B
Need to define two terms
- RPO: Recovery Point Objective
- RTO: Recovery Time Objective
Disaster Recovery Strategies
- Backup and Restore
- Easy, cheap, high RPO, high RTO
- Pilot Light
- A small version of the app is always running in the cloud
- Useful for the critical core (pilot light)
- Very similar to Backup and Restore
- Faster than Backup and Restore as critical systems are already up
- Lower RPO, lower RTO, and we still manage costs
- Warm Standby
- Full system is up and running, but at minimum size
- Upon disaster, we can scale to production load
- Hot Site / Multi Site Approach
- Very low RTO (minutes or seconds) - very expensive
- Full production Scale is running AWS and On-premise
- All AWS Multi Region
- Backup and Restore
DR Tips
- Backup
- EBS Snapshots, RDS automated backups / Snapshots, etc…
- Regular pushes to S3 / S3 IA / Glacier, Lifecycle Policy, CRR
- From On-premise: Snowball or Storage Gateway
- HA
- Use Route 53 to migrate DNS over from Region to Region
- RDS Multi-AZ, ElastiCache Multi-AZ, EFS, S3
- Site-to-Site VPN as a recovery from Direct Connect
- Replication
- RDS Replication (Cross Region), AWS Aurora + Global Databases
- Database replication from on-premise to RDS
- Storage Gateway
- Automation
- CloudFormation / Elastic Beanstalk to recreate a whole new environment
- Recover / Reboot EC2 instance with CloudWatch if alarms fail
- AWS Lambda functions for customized automations
- Chaos
- Netflix has a “simian-army” randomly terminating EC2 instances
- Backup
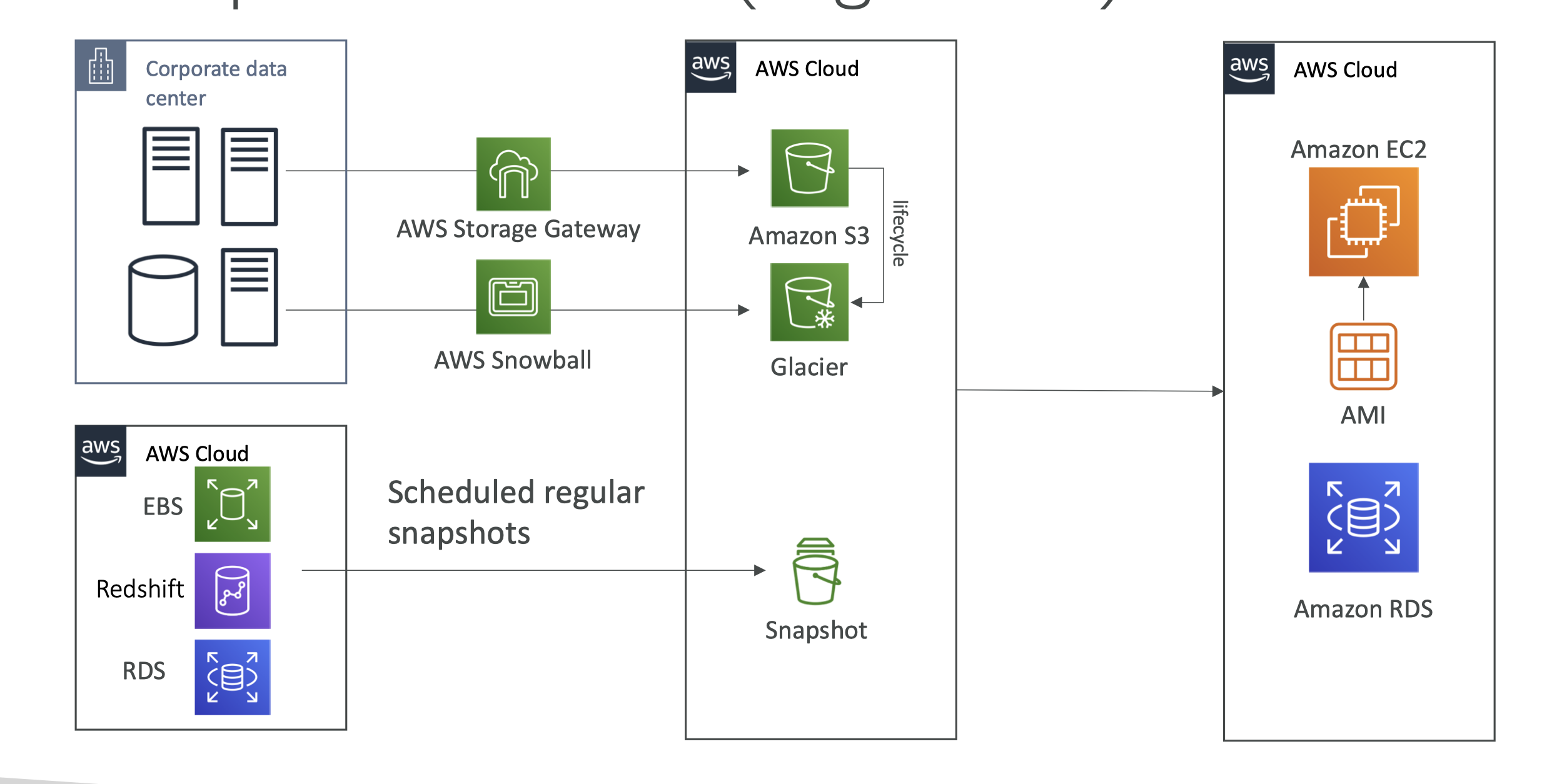
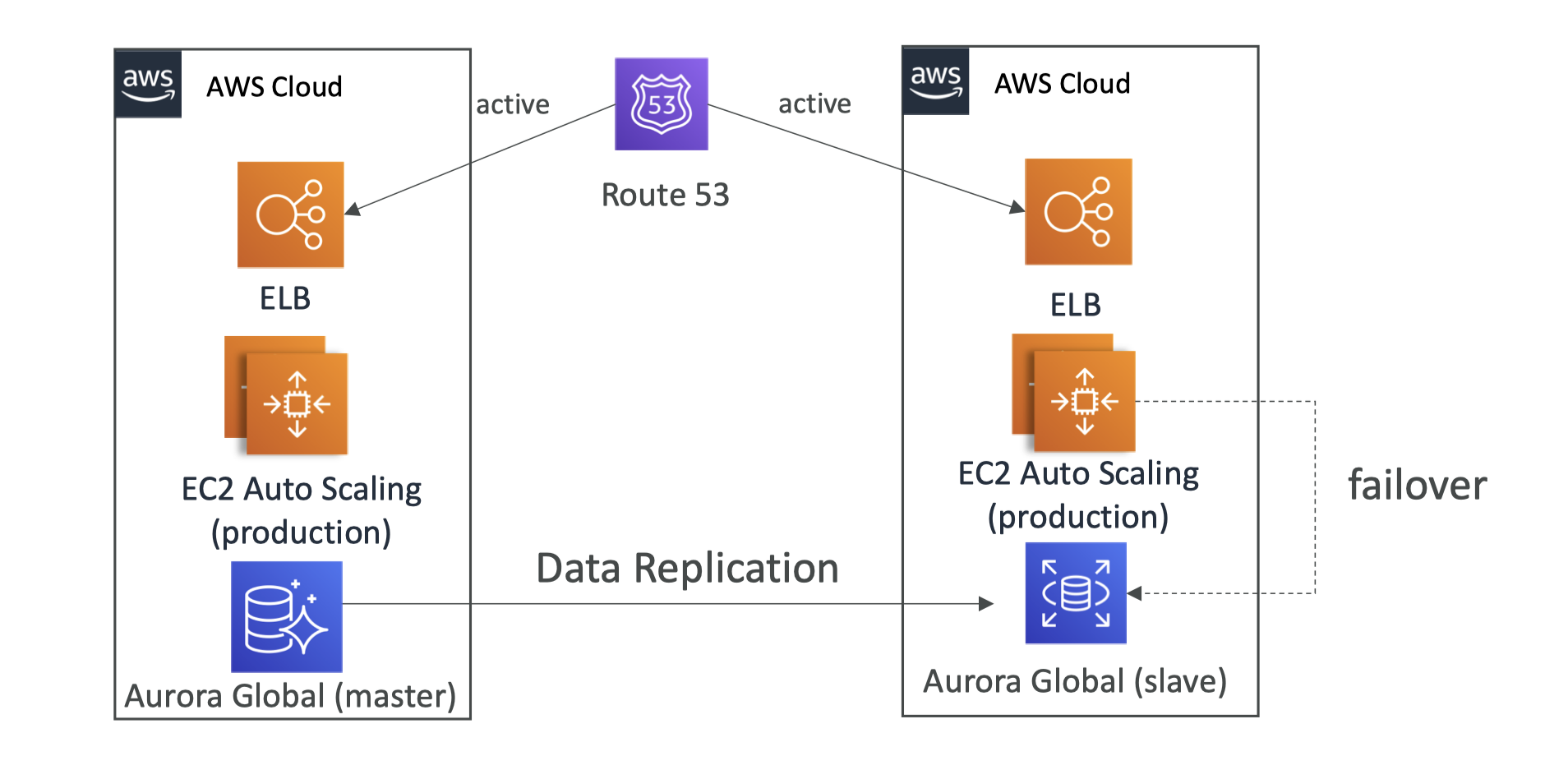
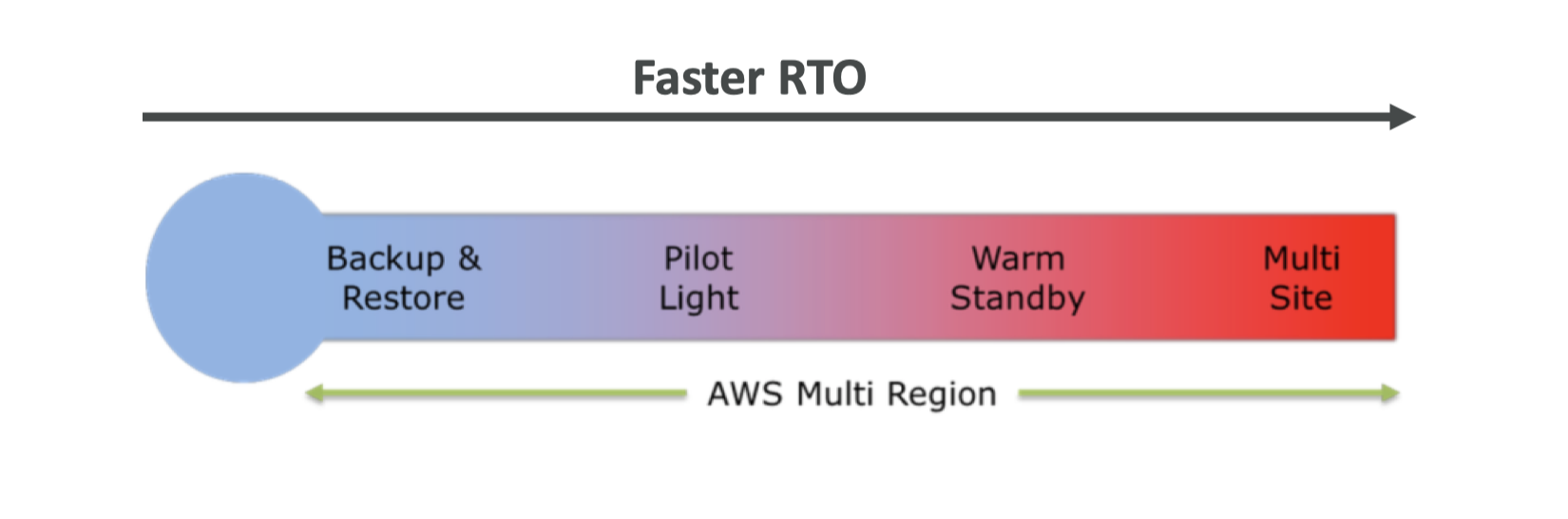
On-Premise Strategy with AWS
- Ability to download Linux 2 AMI as a VM (.iso format)
- VMWare, KVM, VirtualBox (Oracle VM), Microsoft Hyper-V
- VM Import / Export
- Migrate existing applications into EC2
- Create a DR repository strategy for your on-premise VMs
- Can export back the VMs from EC2 to on-premise
- AWS Application Discovery Service
- Gather information about your on-premise servers to plan a migration
- Server utilization and dependency mappings
- Track with AWS Migration Hub
- AWS Database Migration Service (DMS)
- replicate On-premise => AWS, AWS => AWS, AWS => On-premise
- Works with various database technologies (Oracle, MySQL, DynamoDB, etc…)
- AWS Server Migration Service (SMS)
- Incremental replication of on-premise live servers to AWS
CI/CD
Continuous Integration
- Developers push the code to a code repository often
- A testing / build server checks the code as soon as it’s pushed (CodeBuild / Jenkins CI)
- The developers gets feedback about the tests and checks that have passed / failed
- Find bugs early, fix bugs
- Deliver faster as the code is tested
- Deploy often
Continuous Delivery
- Ensure that the software can be released reliably whenever needed
- Ensure deployments happen often and are quick
- Shift away from “one release every 3 months” to “5 releases a day”
- That usually means automated deployment
- CodeDeploy
- Jenkins CD
- Spinnaker
Tech Stack for CI/CD
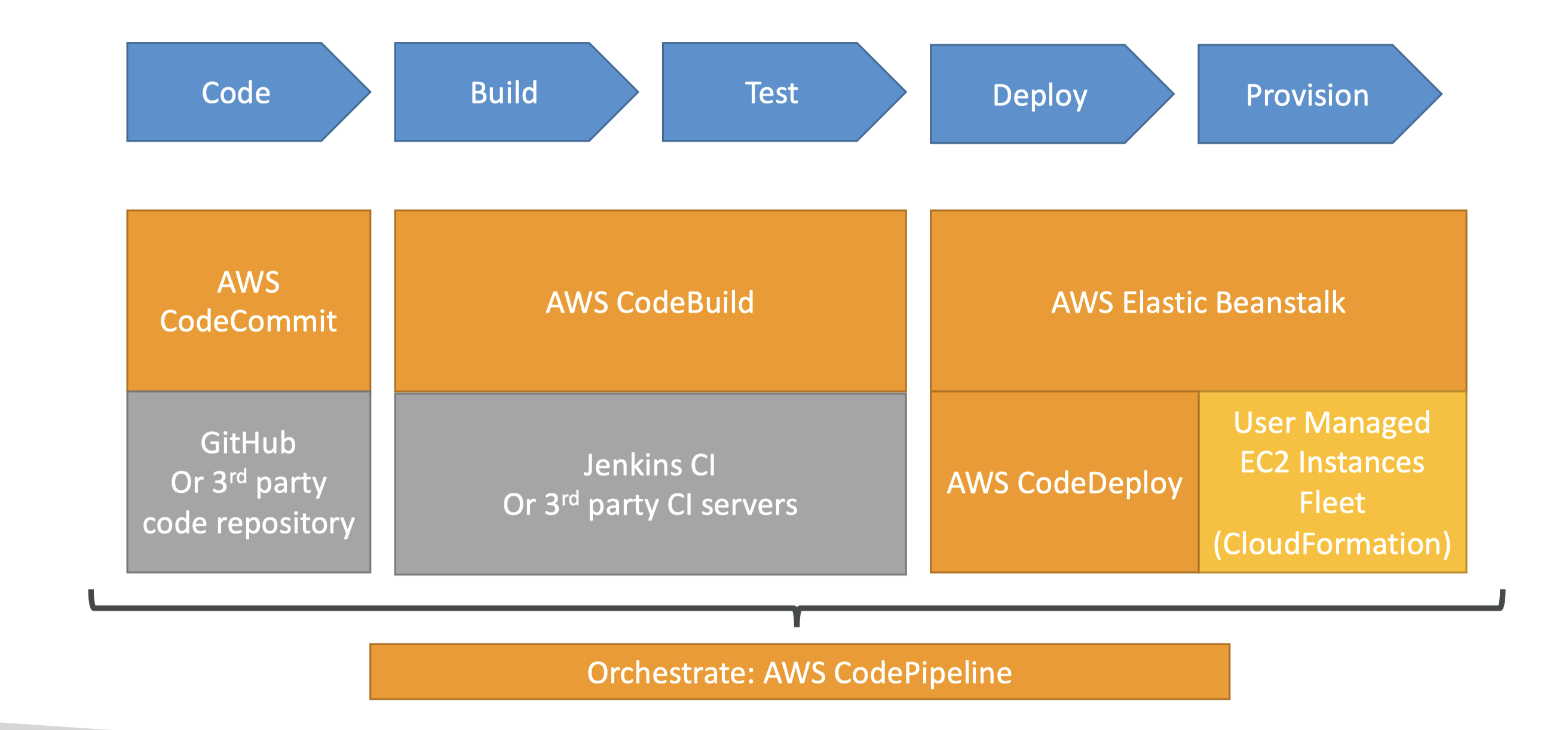
Classic Solution Architecture
Stateless Web App
- Progressively
- Public EC2 + Elastic IP
- Multi Public EC2s + Elastic IP for each one
- Route 53 + Public EC2s (without Elastic IP)
- visiting same hostname
- Route 53 + ELB (with Health Checks) + Private EC2s in one AZ
- Route 53 + ELB (with Health Checks) + Private EC2s in different AZs
- Minimum 2 AZ for cost saving
Stateful Web App
- Progressively
- Route 53 + ELB + Private EC2s in different AZs
- Route 53 + ELB (with Stickness) + Private EC2s in diff AZs
- Using ElasticCache for Storing / Retrieving session data
- Storing session data into a database (DynamoDB)
- Scaling reads of DynamoDB (Read Replicas)
- Read from ElastiCache
- Multi AZ for ElastiCache and DynamoDB
- Restrict traffic only from EC2 to ElastiCache or DynamoDB
Summary
- ELB sticky sessions
- Web clients for storing cookies and making our web app stateless
- ElastiCache
- For storing sessions (alternative: DynamoDB)
- For caching data from DB
- Multi AZ
- RDS
- For storing user data
- Read replicas for scaling reads
- Multi AZ for DR
- Tight Security with SGs referencing each other
WordPress Blog Website
- Progressively
- Route 53 + ELB + EC2s in diff AZs + RDS with Multi AZ
- Route 53 + ELB + EC2s in diff AZs + Aurora MySQL with Multi AZ and Read Replicas
- Storing images with EBS
- Storing images with EFS
- Progressively
Typical Architecture
Application Shards
- Sharding is a common concept to split data across multiple tables in a database
- To make future growth easier, we make use of application shards
- By using this, we can distribute the load to best suit our needs
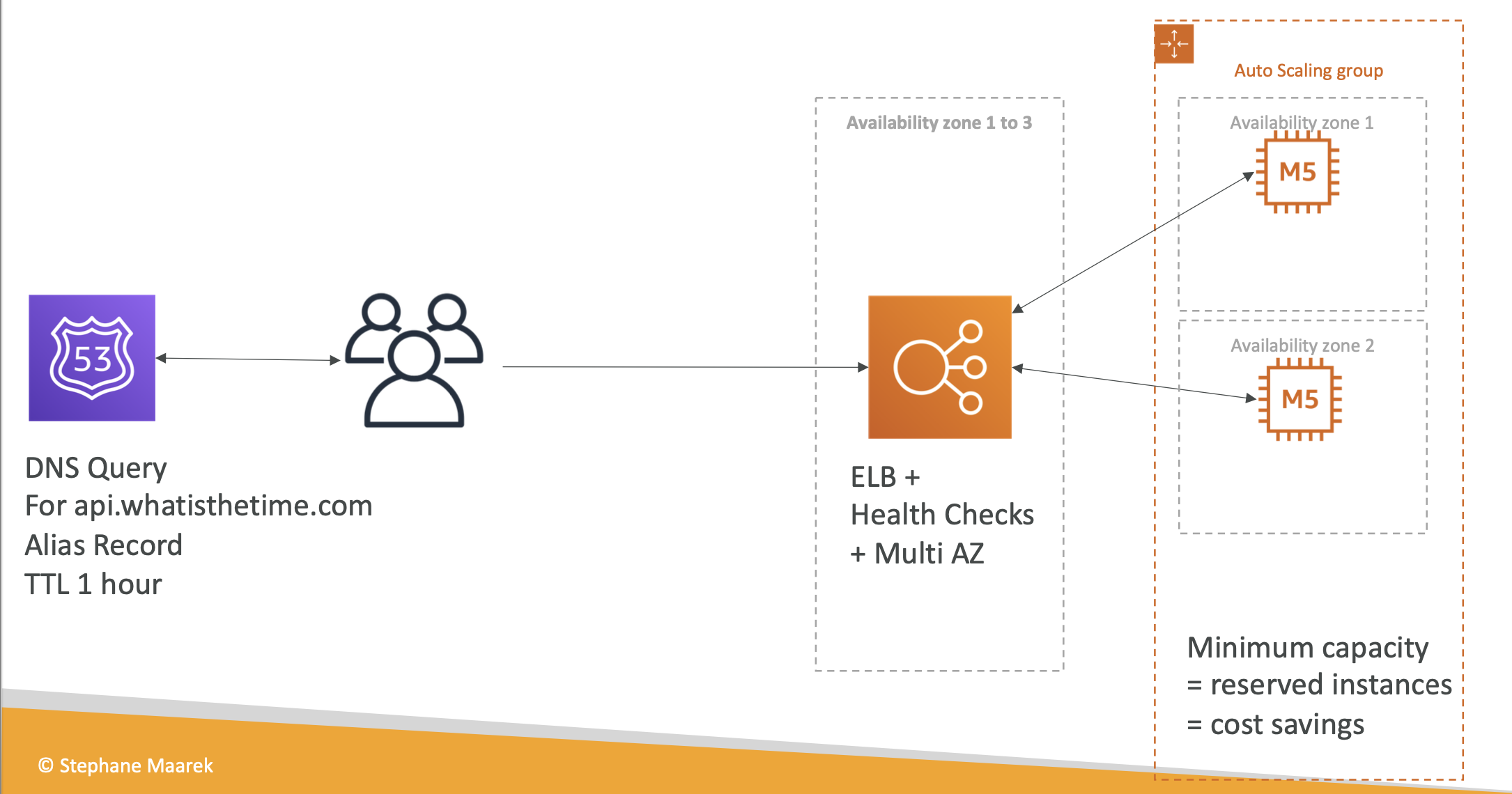
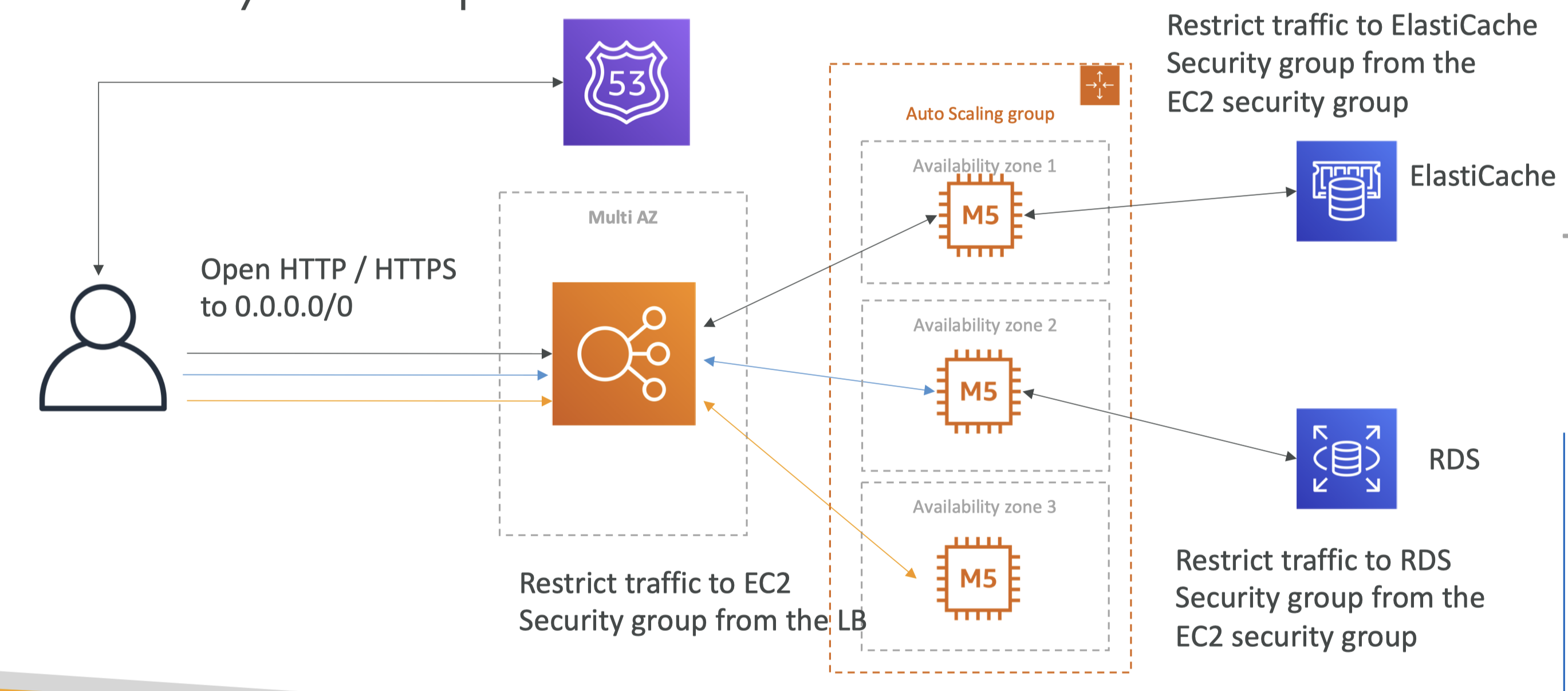
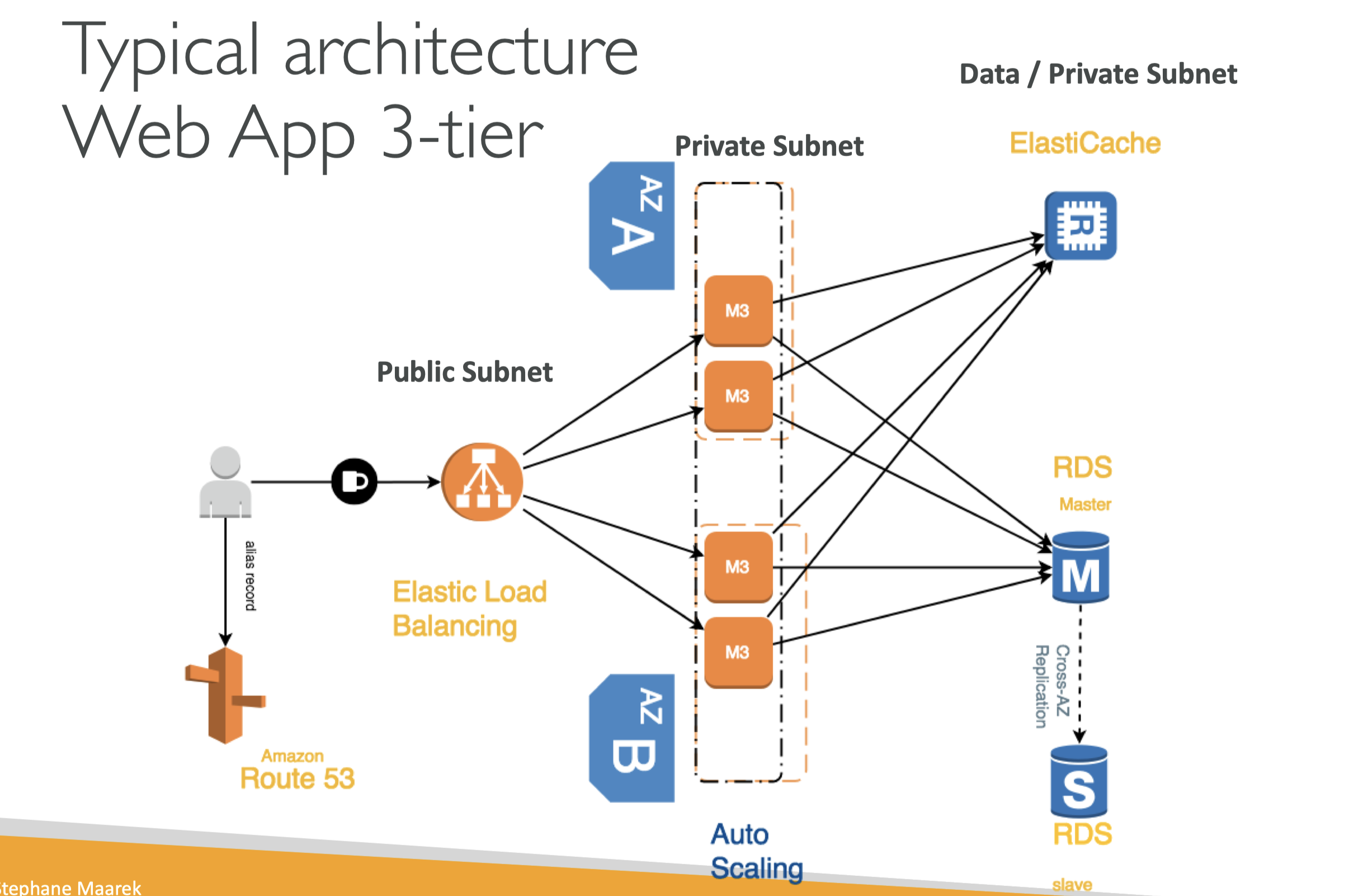
Serverless Solution Architecture
- Mobile App
- Progressively
- API Gateway + Cognito + Lambda + DynamoDB
- S3 + STS (giving users access to S3, using Cognito to generate temporary credentials with STS to access S3 bucket with restricted policy)
- DAX (using DAX before DynamoDB for high read throughput)
- Caching at the API Gateway
- Serverless hosted website
- Serving static content, globally
- Serving static content, globally, securely
- Adding a public serverless REST API
- Leveraging DynamoDB Global Tables
- User Welcome email flow
- Thumnail generation flow
- Serving static content, globally
- Microservices
- Synchronous patterns: API Gateway, ELB
- Asynchronous patterns: SQS, Kinesis, SNS, Lambda
- Distributing Paid Content
- Simple, premium user service
- Add authentication
- Add Video Storage Service
- Distribute Globally and Securely
- Distribute Content only to Premium Users
- Summary
- Cognito for authentication
- DynamoDB for storing users that are premium
- 2 Serverless applications
- Premium User registration
- CloudFront Signed URL generator
- Content is stored in S3 (Serverless and scalable)
- Integrated with CloudFront with OAI for security
- CloudFront can only be used using Signed URLs to prevent unauthorized users
- Simple, premium user service
- Software updates offloading
- Current Architecture
- Using CloudFront to fix
- Why CloudFront?
- No changes to architecture
- Will cache software update files at the edge
- Software update files are not dynamic, they’re static (never changing)
- Our EC2 instance aren’t serverless
- But CloudFront is, and will scale for us
- Our ASG will not scale as much, and we’ll save tremendously in EC2
- We’ll also save in availability, network bandwidth cost, etc…
- Easy way to make an existing application more scalable and cheaper
- Current Architecture
- Big Data Ingestion Pipeline
- Summary
- Kinesis is great for real-time data collection
- Firehose helps with data delivery to S3 in near real-time (1 min)
- Lambda can help Firehose with data transformation
- S3 can trigger notification to SQS
- Lambda can subscribe to SQS
- Athena is a serverless SQL service and results are stored in S3
- The reporting bucket contains analyzed data and can be used by reporting tool such as QuickSight, Redshift, etc…
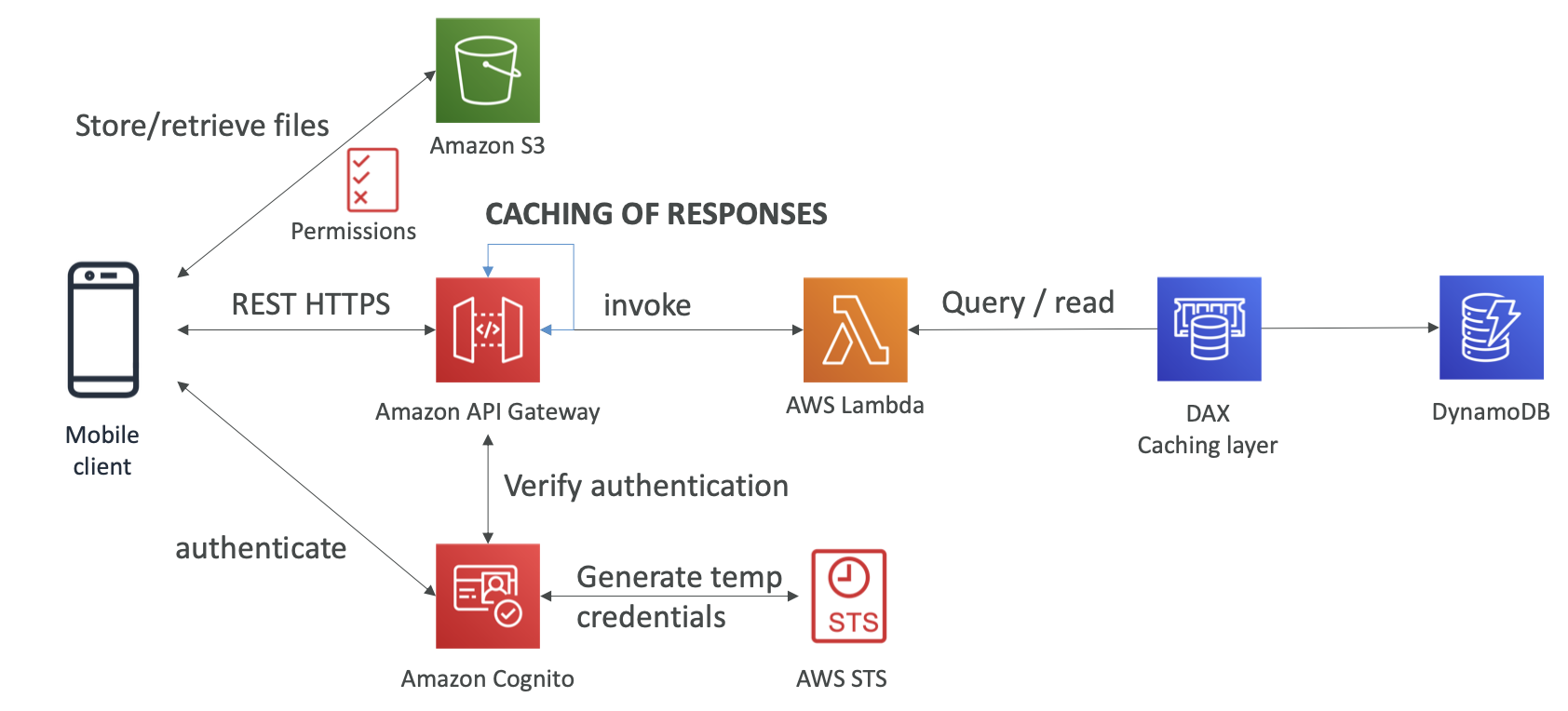

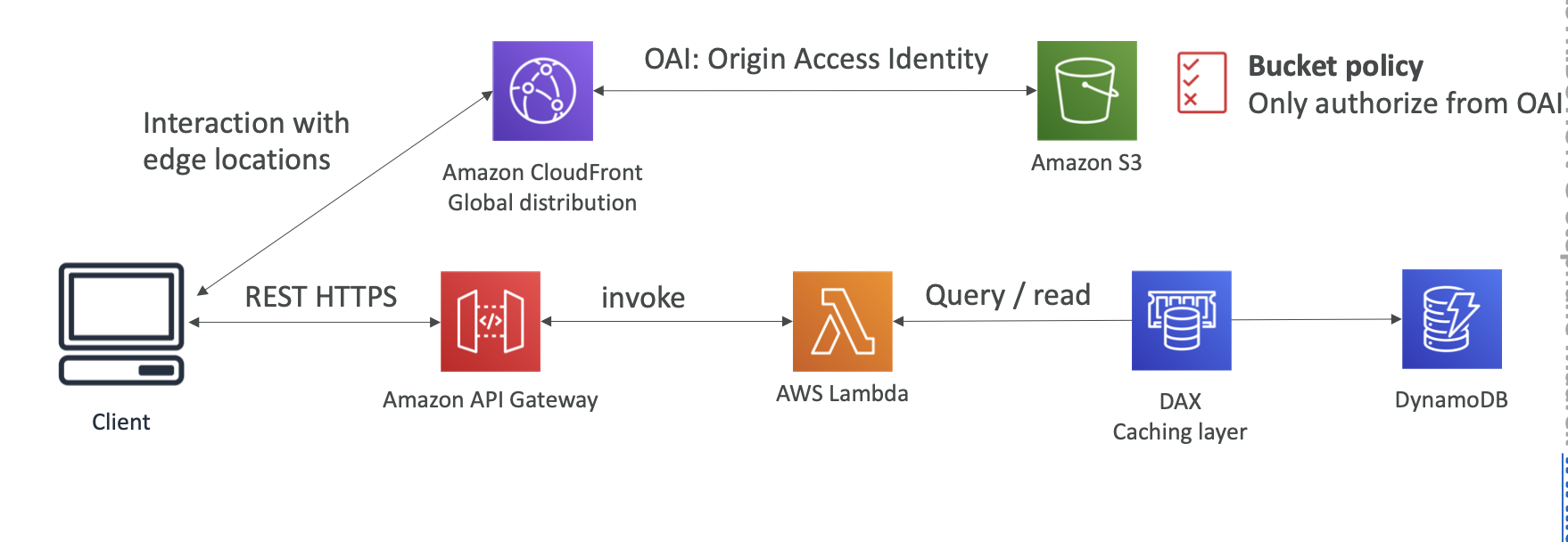
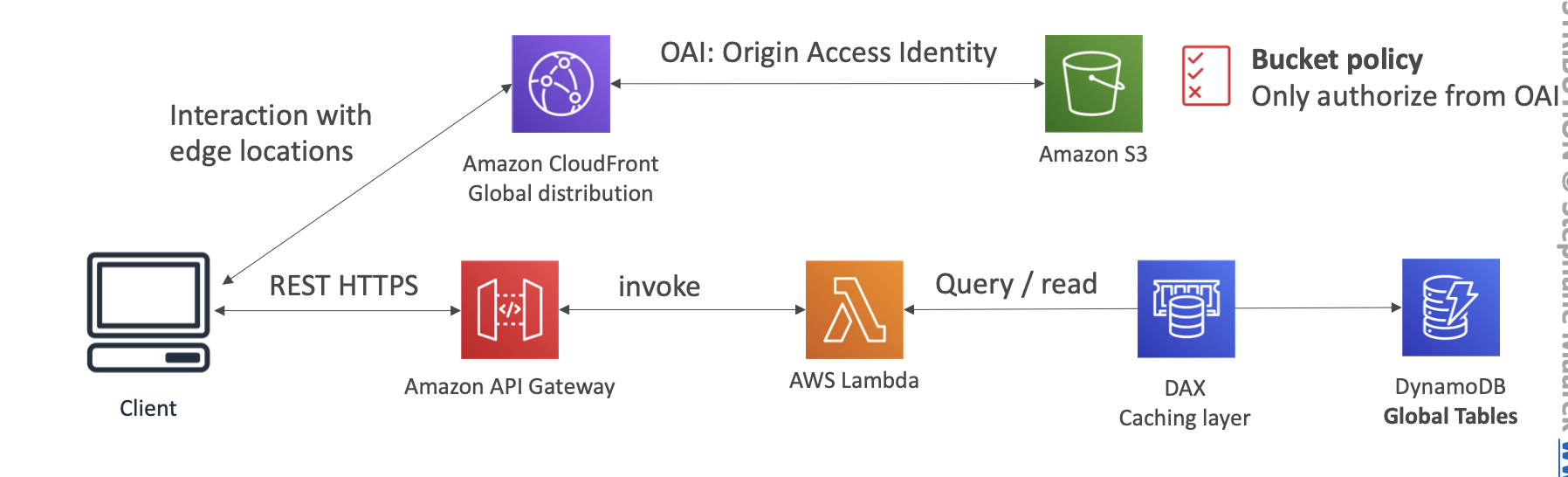
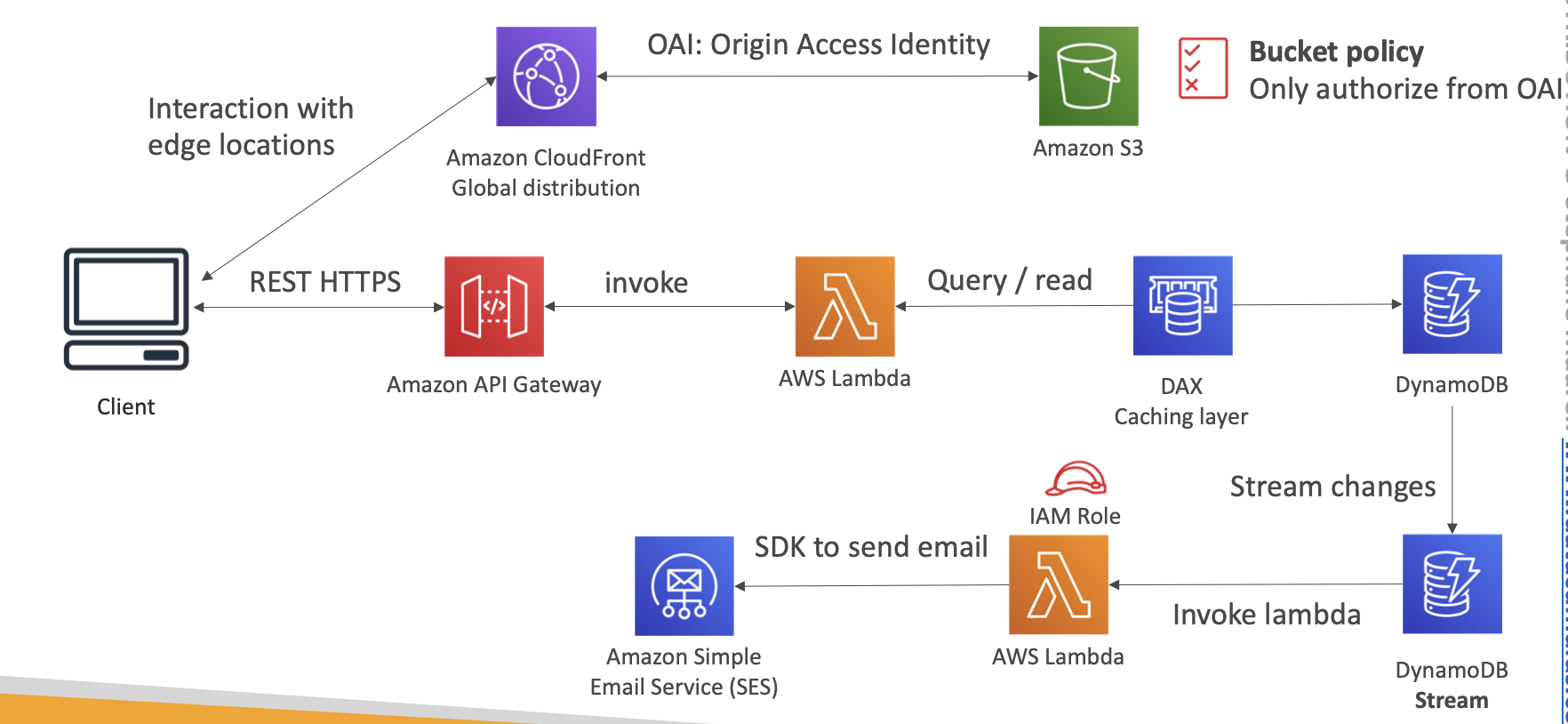
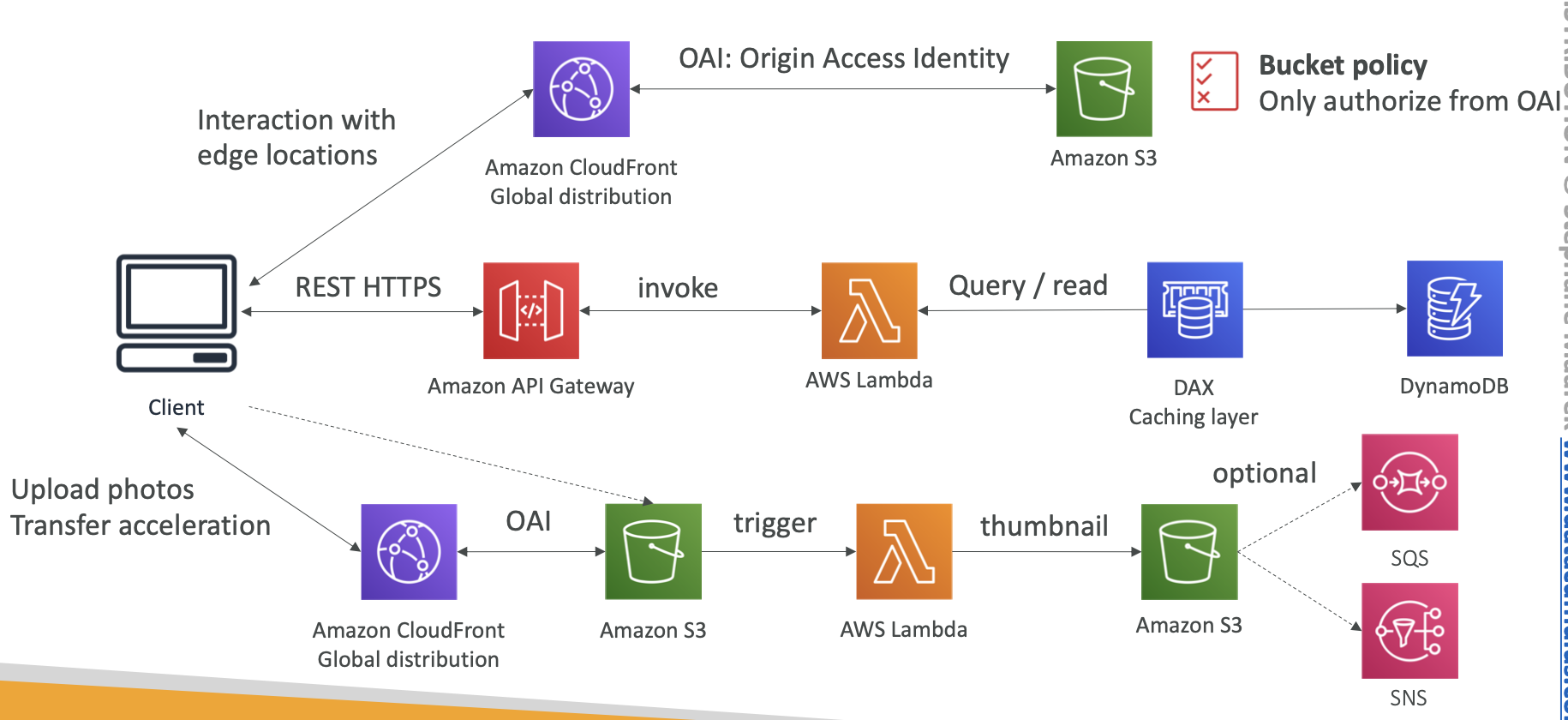
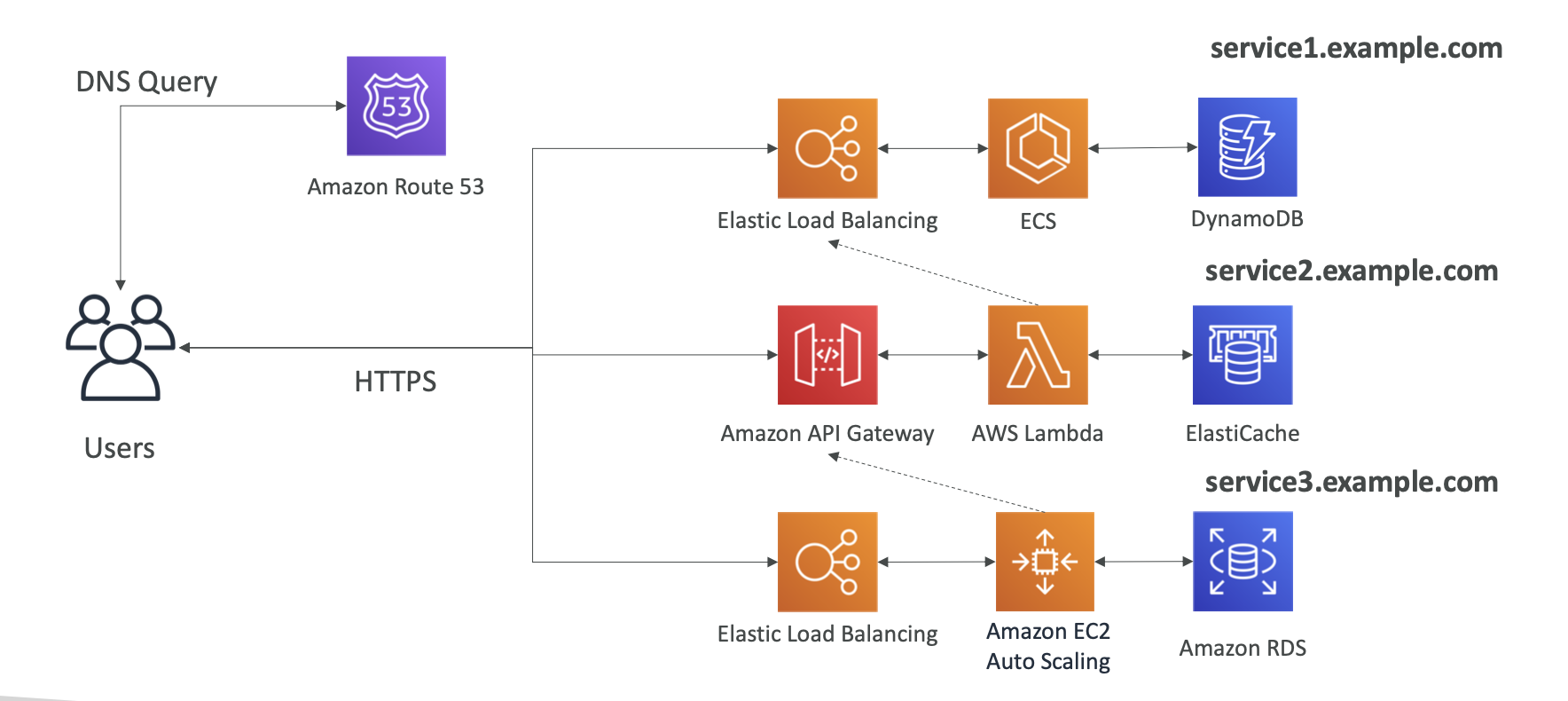
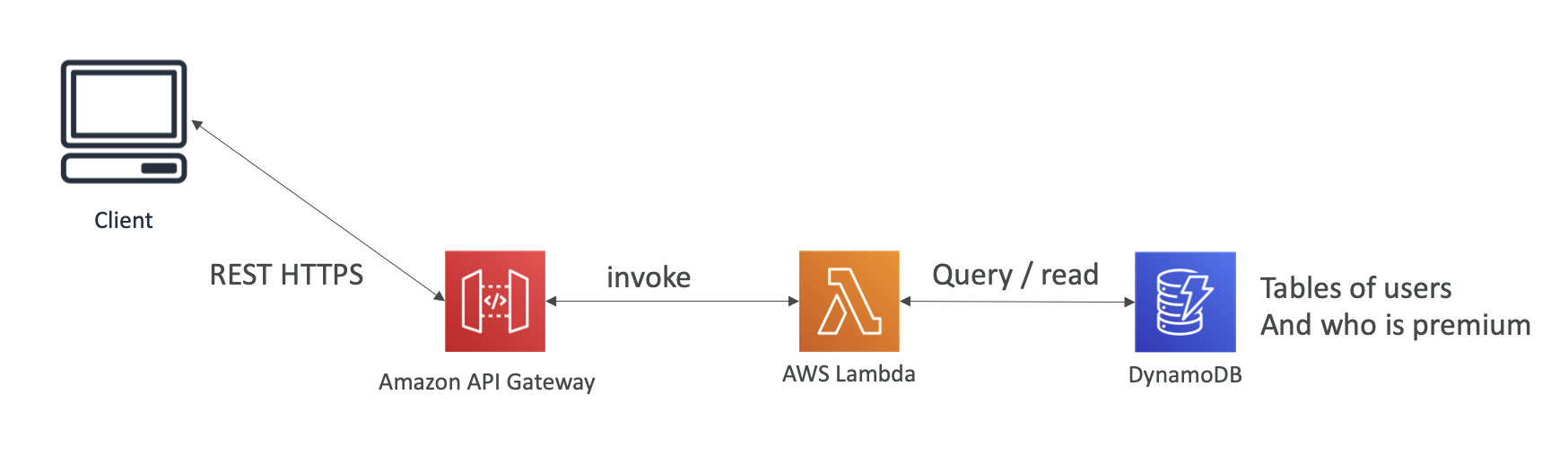
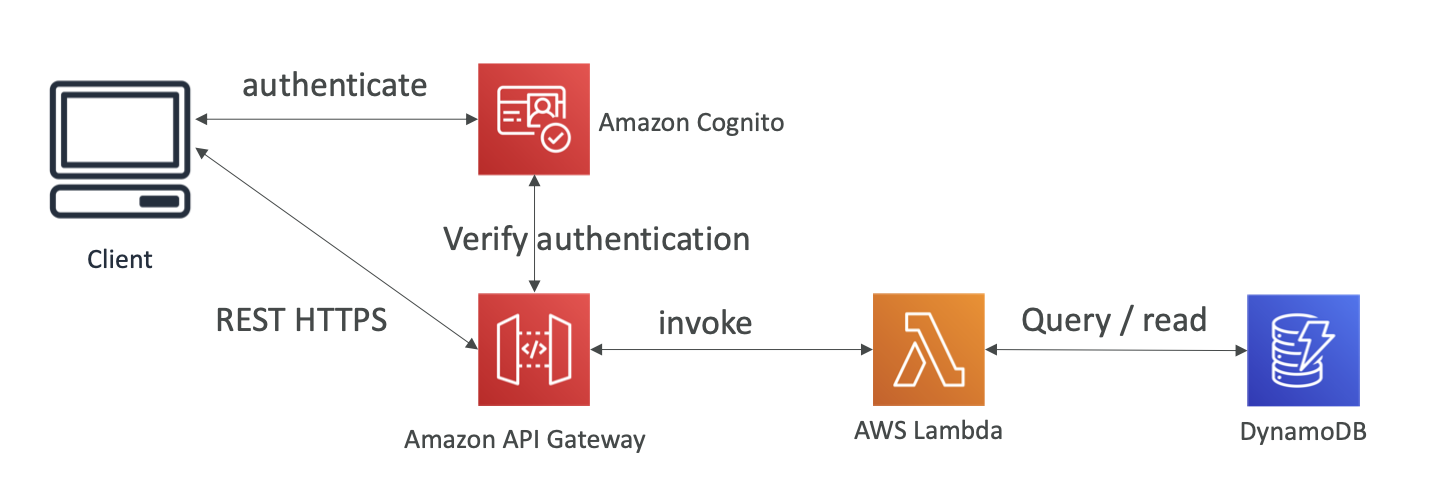
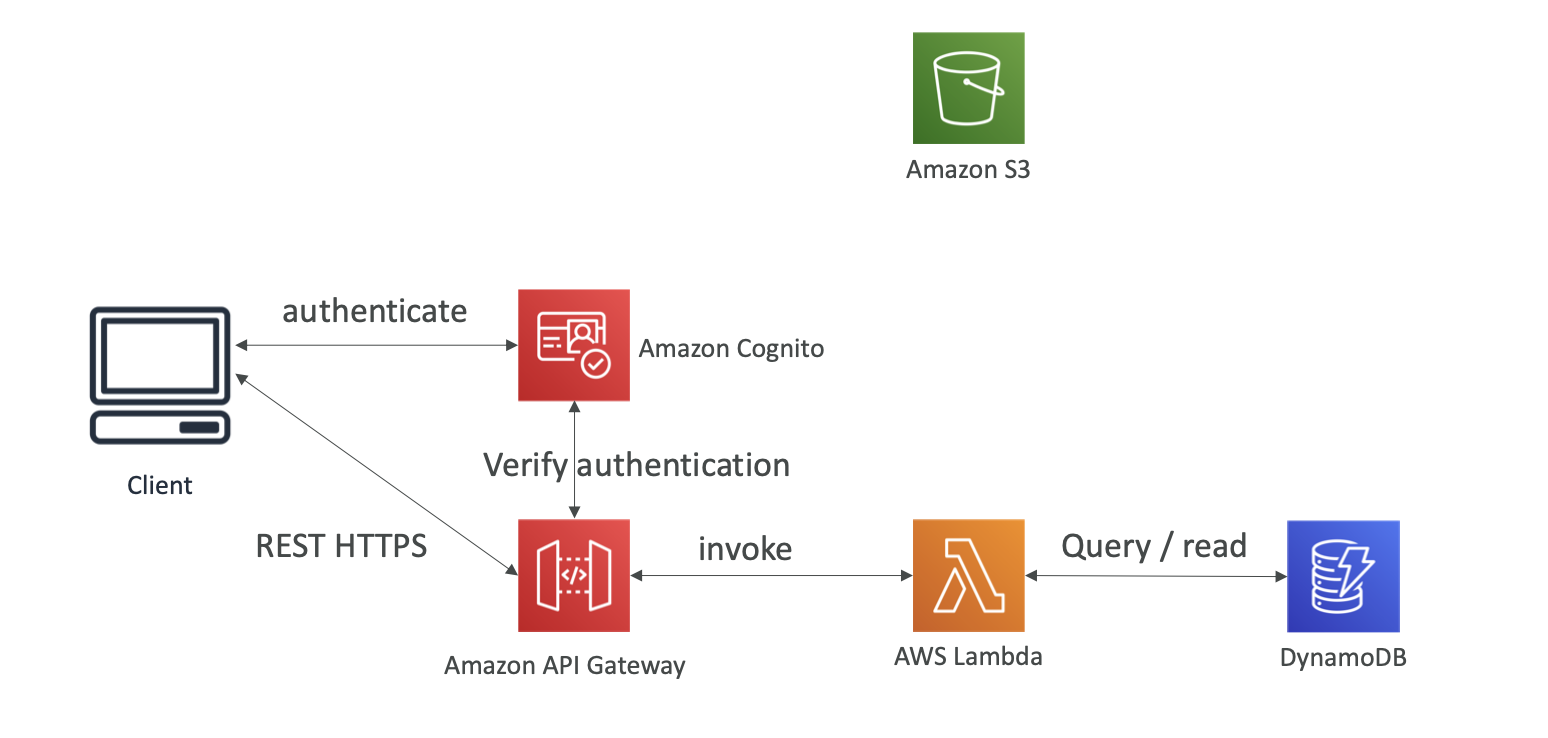
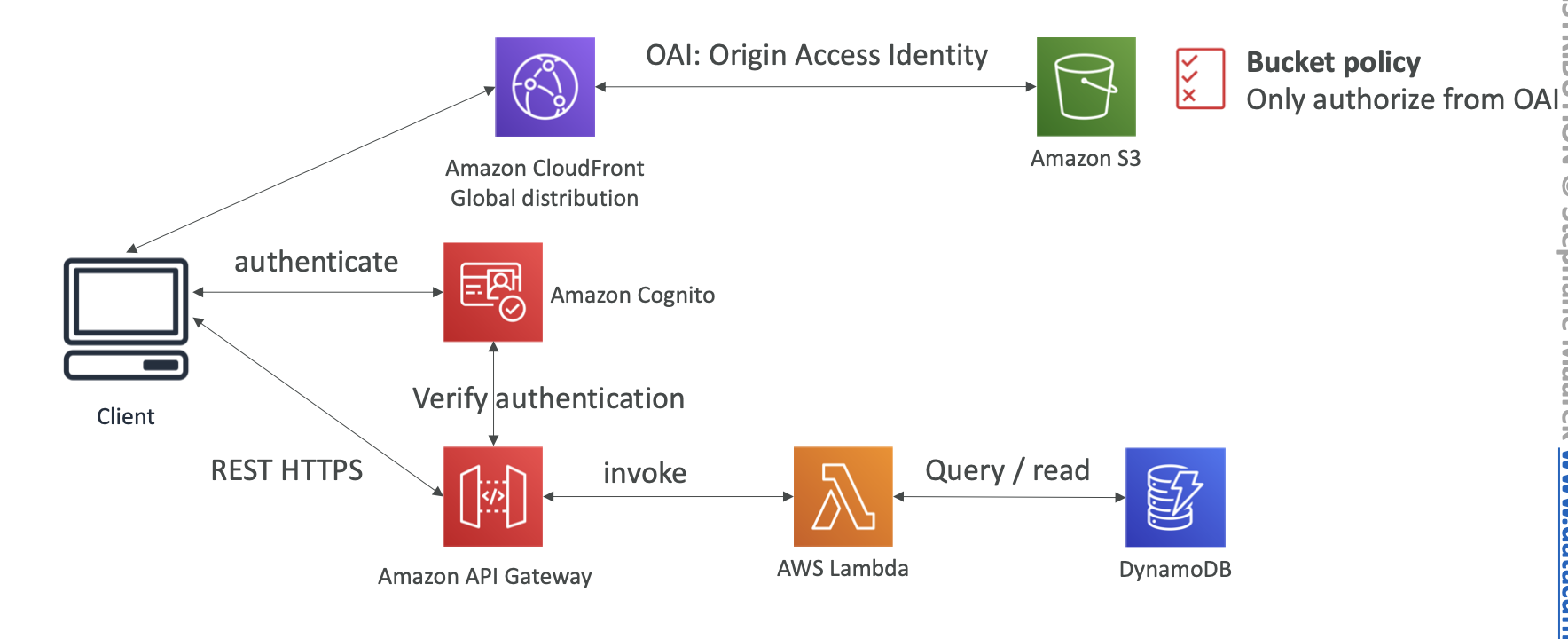
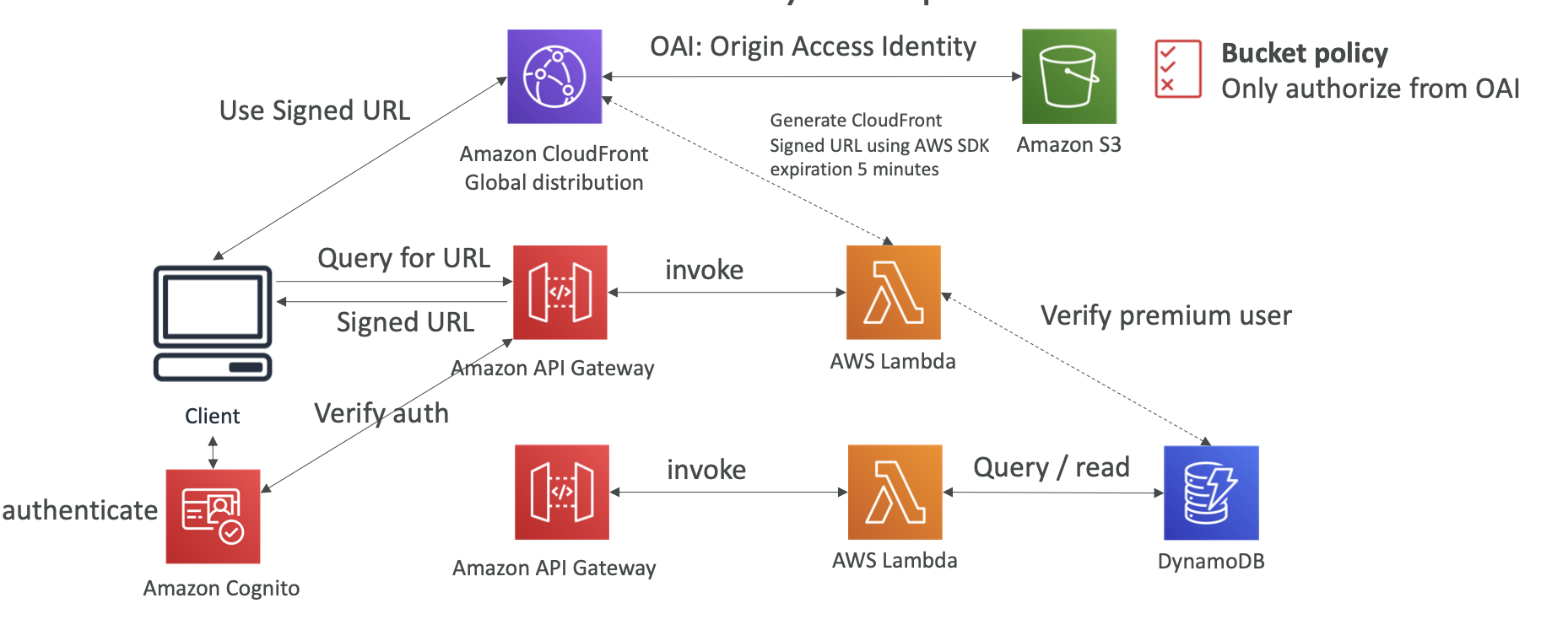
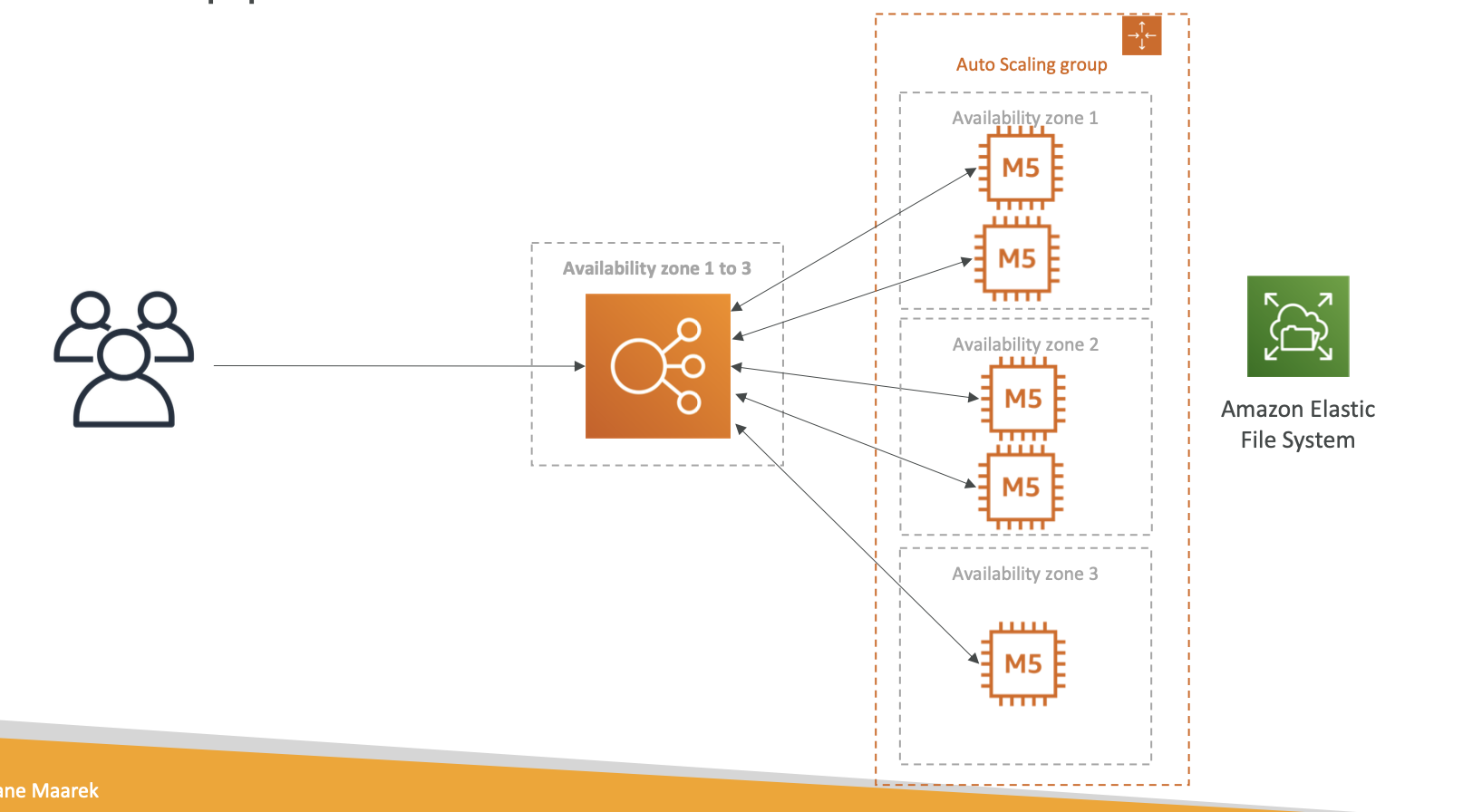
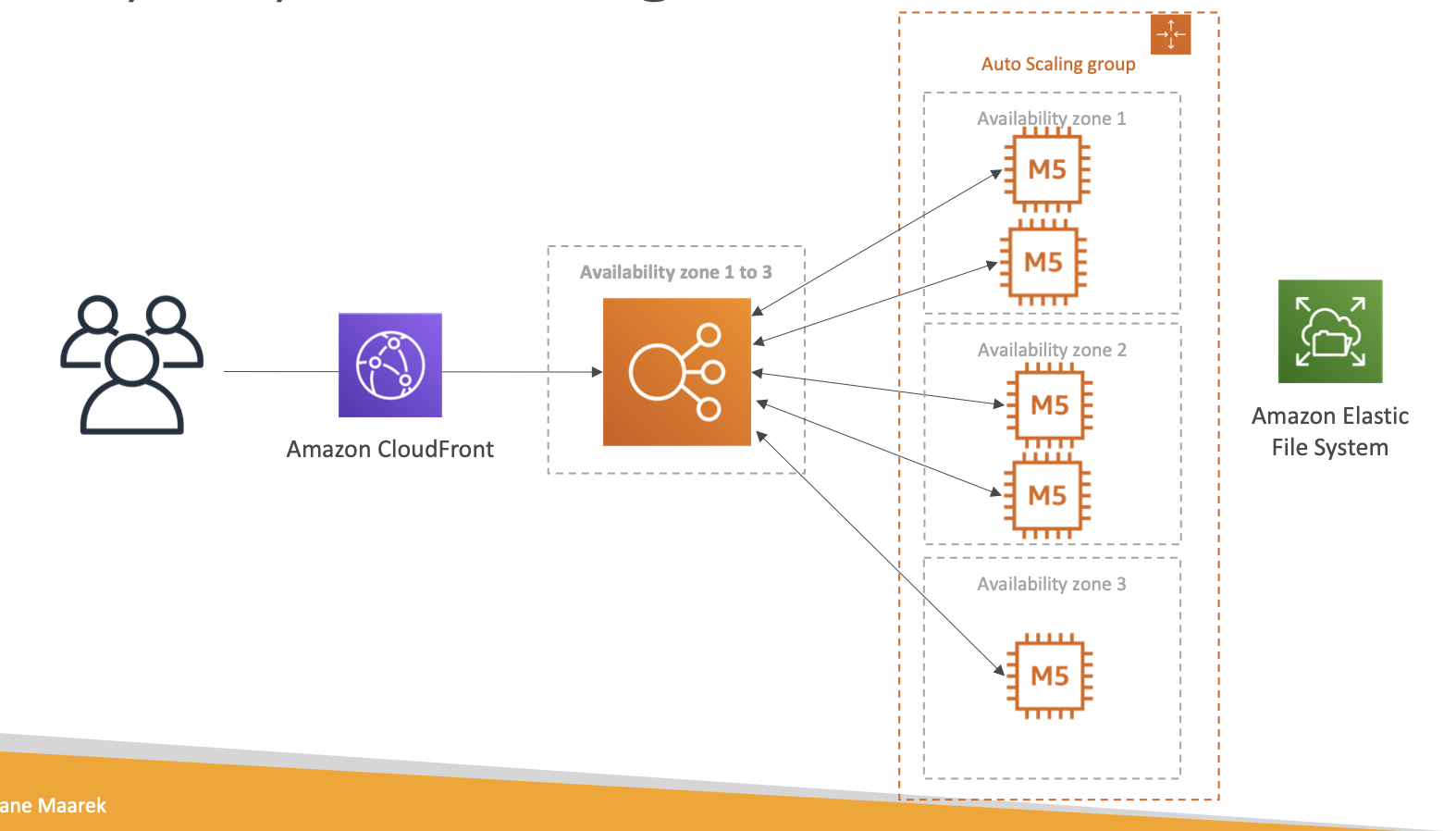
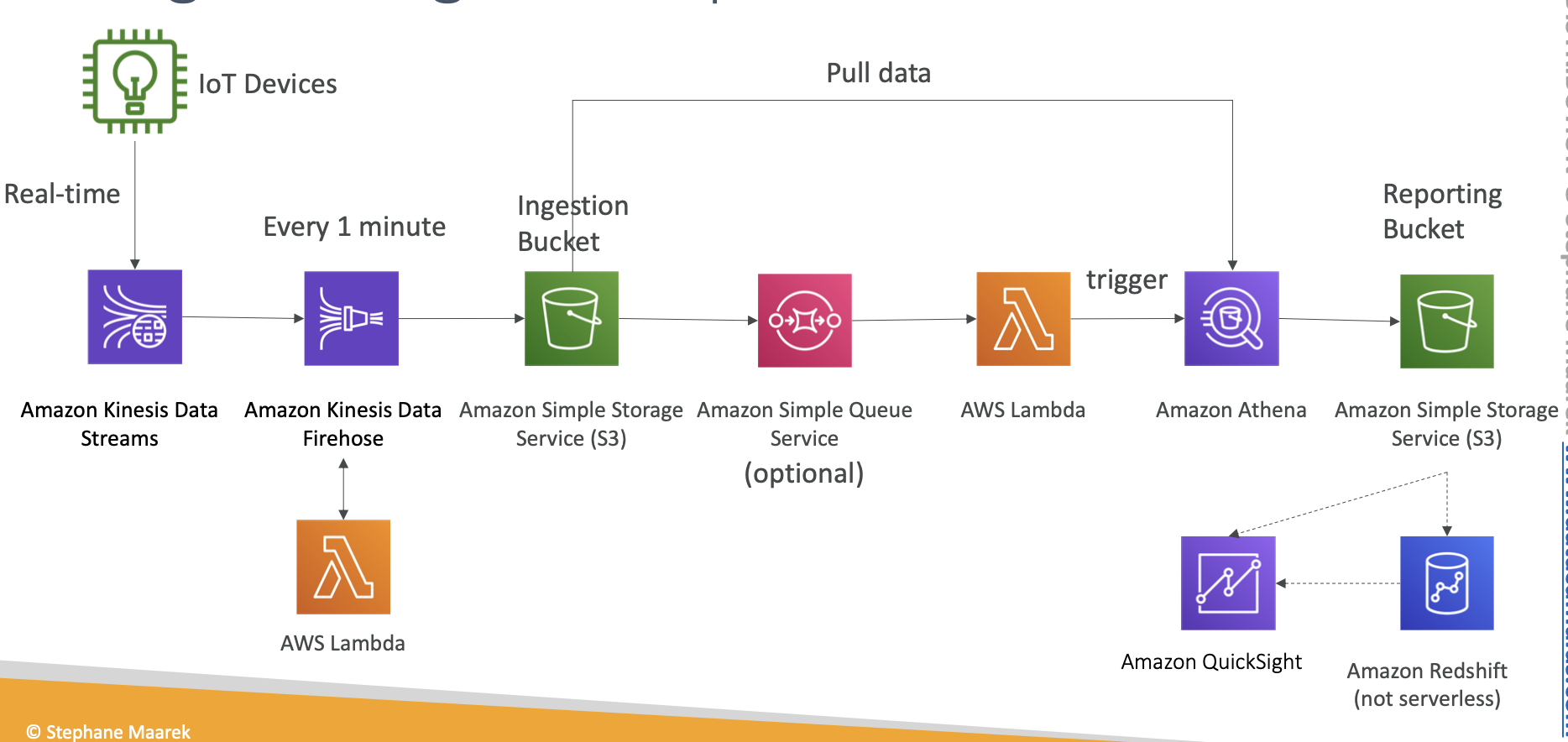
Other Architectures
Serverless: S3, Lambda, DynamoDB, CloudFront, API Gateway
- Event Processing
- Lambda, SNS & SQS
- SQS + Lambda + SQS DLQ
- SQS FIFO + Lambda + SQS DLQ
- SNS + Lambda + SQS DLQ
- Fan Out Pattern (deliver to multiple SQS)
- S3 Event
- if you want to ensure that an event notification is sent for every successful write, you can enable versioning on your bucket
- Lambda, SNS & SQS
- Caching Strategies
- Using TTL for renewing the cache of CloudFront
- API Gateway also have some caching capability
- Since API Gateway is a regional service, so the cache of API Gateway is also regional
- Apps can do cache in Redis, Memcached, or DAX and reduce the pressure of database
- Note: there is no caching capability in S3 and Databases
- Blocking an IP address
- Client -> EC2
- Using NACLs deny rule for blocking
- Client -> ALB -> EC2
- Usig ALB connection termination
- The SG of EC2 must only allows the traffic from the SG of ALB, not from the client
- Client -> NLB -> EC2
- NLB cannot do connection termination
- No SG for NLB
- all traffic go through NLB to EC2 without any obstacle
- Client -> ALB + WAF -> EC2
- Client -> CloudFront + WAF -> ALB -> EC2
- If the CloudFront stands before ALB, the NACL cannot get the IP address of the client. So, using NACL to block IP address will fail
- Client -> EC2
- HPC
- Data Management & Transfer
- Direct Connect
- Move GB/s of data to the cloud, over a private secure network
- Snowball & Snowmobile
- Move PB of data to the cloud
- DataSync
- Move large amount of data between on-premise and S3, EFS, FSx for Windows
- Direct Connect
- Compute & Networking
- EC2 Instances
- CPU Optimized, GPU Optimized
- Spot Instances / Spot Fleets for cost savings + Auto Scaling
- EC2 Placement Groups: Cluster for good network performance
- EC2 Enhanced Networking (SR-IOV)
- Higher bandwidth, higher PPS (packet per second), low latency
- Option 1: Elastic Network Adapter (ENA) up to 100Gbps
- ENA is a custom network interface optimized to deliver high throughput and low latency on specific supported EC2 instance
- It doesn’t support high-performance requirements
- Not all instance types are supported for using ENA interface
- user can enable it with “-ena-support”
- Option 2: Intel 82599 VF up to 10Gbps - Legacy
- Elastic Fabric Adapter (EFA)
- Imporved ENA for HPC and machine learning, only works for Linux
- EFA supports low latency and high throughput with high-performance with the scalability, flexibility, and elasticity provided by AWS.
- Great for inter-node communications, tightly coupled workloads
- Leverages Message Passing Interface (MPI) standard
- Bypasses the underlyingn Linux OS to provide low-latency reliable transport
- EFA cannot be moved into another subnet once created.
- Amazon CloudWatch metrics are required to monitor EFA in Real-Time
- EFA OS-bypass subnet is limited to only one subnet.
- To enable OS-bypass functionality, the EFA must be a member of security group that allows inbound and outbound traffic and from the security group itself.
- Attach & Detach
- Attach: Only one EFA can be attached to an EC2 instance (stopped state, not running state)
- Detach: You must stop the instance first. You cannot detach an EFA from a running instance
- You can change the IP addresses associated with an EFA. If you have an Elastic Ip address, you can associate it with an EFA
- EC2 Instances
- Storage
- Instance-attached storage
- EBS: scale up to 64000 IOPS with io1 Provisioned IOPS
- Instance Store: scale to millions of IOPS, linked to EC2 instance, low latency
- Network storage
- S3: large blob, not a file system
- EFS: scale IOPS based on total size, or use Provisioned IOPS
- FSx for Lustre
- HPC optimized distributed system, millions of IOPS
- Backed by S3
- Instance-attached storage
- Automation & Orchestration
- AWS Batch
- Batch supports multi-node parallel jobs, which enables you to run single jobs that span multiple EC2 instances
- Easily schedule jobs and launch EC2 instances accordingly
- AWS ParallelCluster
- Open source cluster management tool to deploy HPC on AWS
- Configure with text files
- Automate creation of VPC, Subnet, cluster type and instance types
- AWS Batch
- Data Management & Transfer
- Creating a highly available EC2 instance
- Using CloudWatch Event to trigger
- Using CloudWatch to monitoring the metrics of EC2 instances. After that CloudWatch Event can trigger a Lambda Function to do whatever you want
- ASG
- EC2 instance attaching User Data which contains scripts for attaching Elastic IP to that instance
- When one instance is terminated, other one will be created by ASG, and this new instance will run User Data automatically
- ASG + EBS
- EBS is AZ specific service
- Using ASG lifecycle hooks for creating a new EBS volume in another AZ
- Using CloudWatch Event to trigger
- HA for Bastion Host
- HA Options for the bastion host
- Run 2 across 2 AZ
- Run 1 across 2 AZ with 1 ASG 1:1:1
- Routing to the bastion host
- if 1 bastion host, use an Elastic IP with EC2 User Data script to access it
- if 2 bastion host, use NLB(Layer 4) deployed in multiple AZ
- if NLB, the bastion hosts can live in the private subnet directly
- Note: Can’t use ALB as the ALB is in layer 7
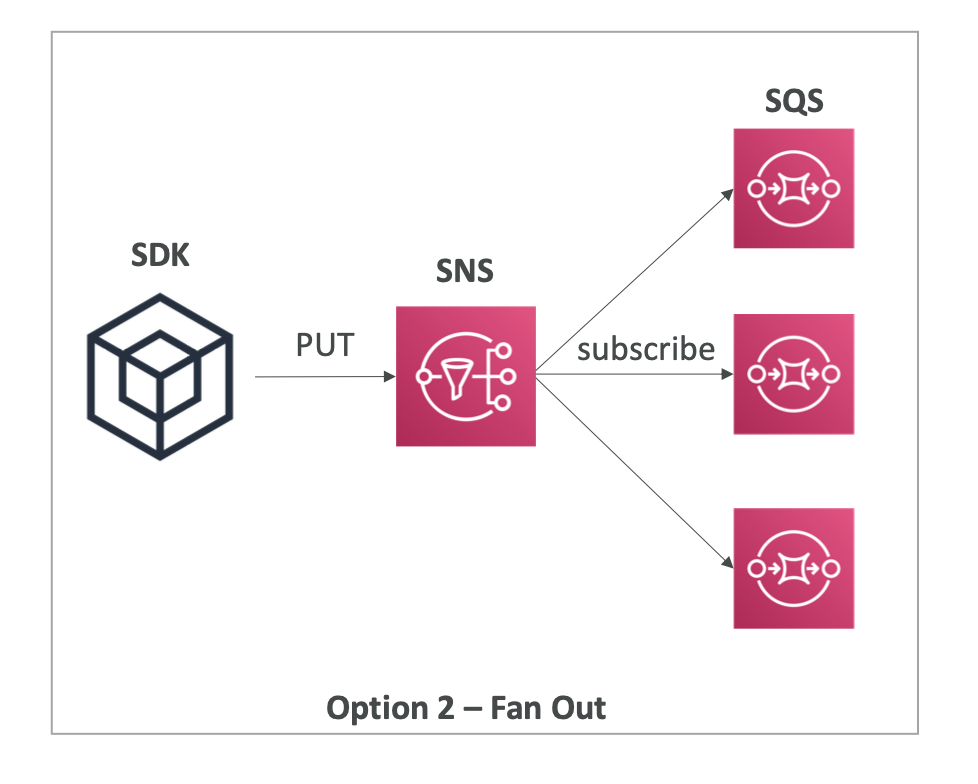
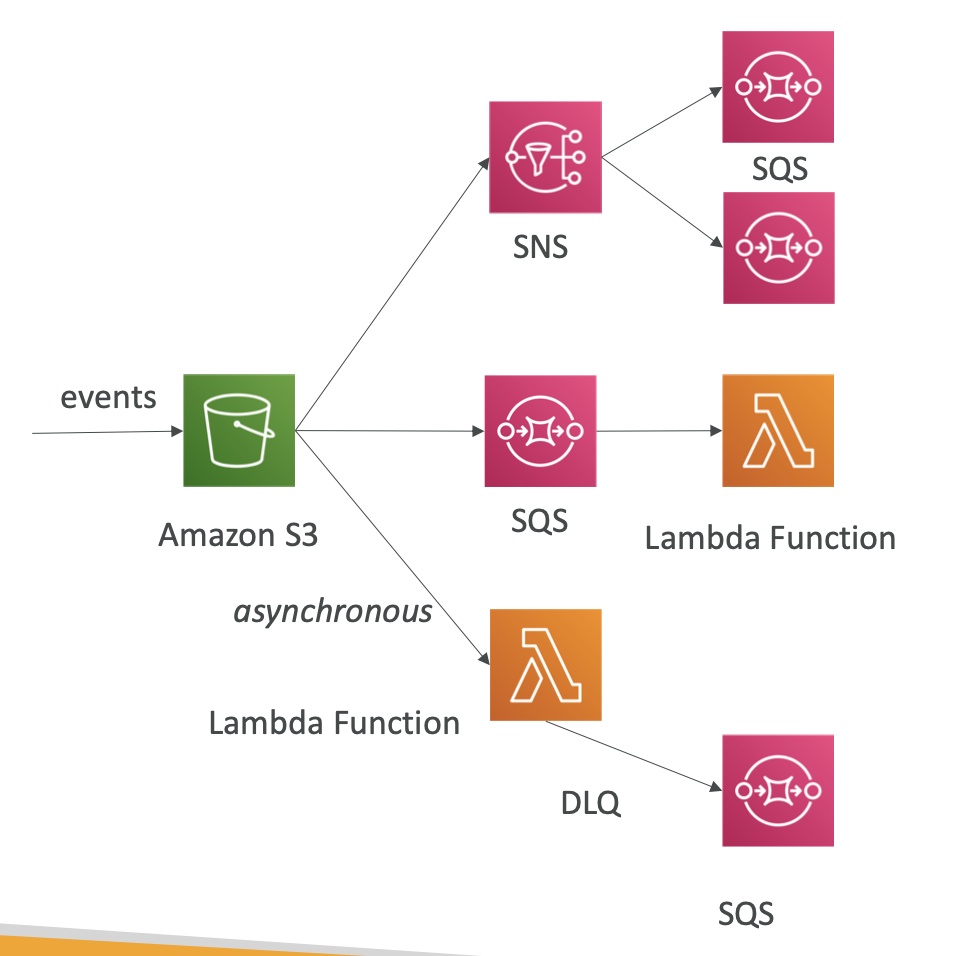
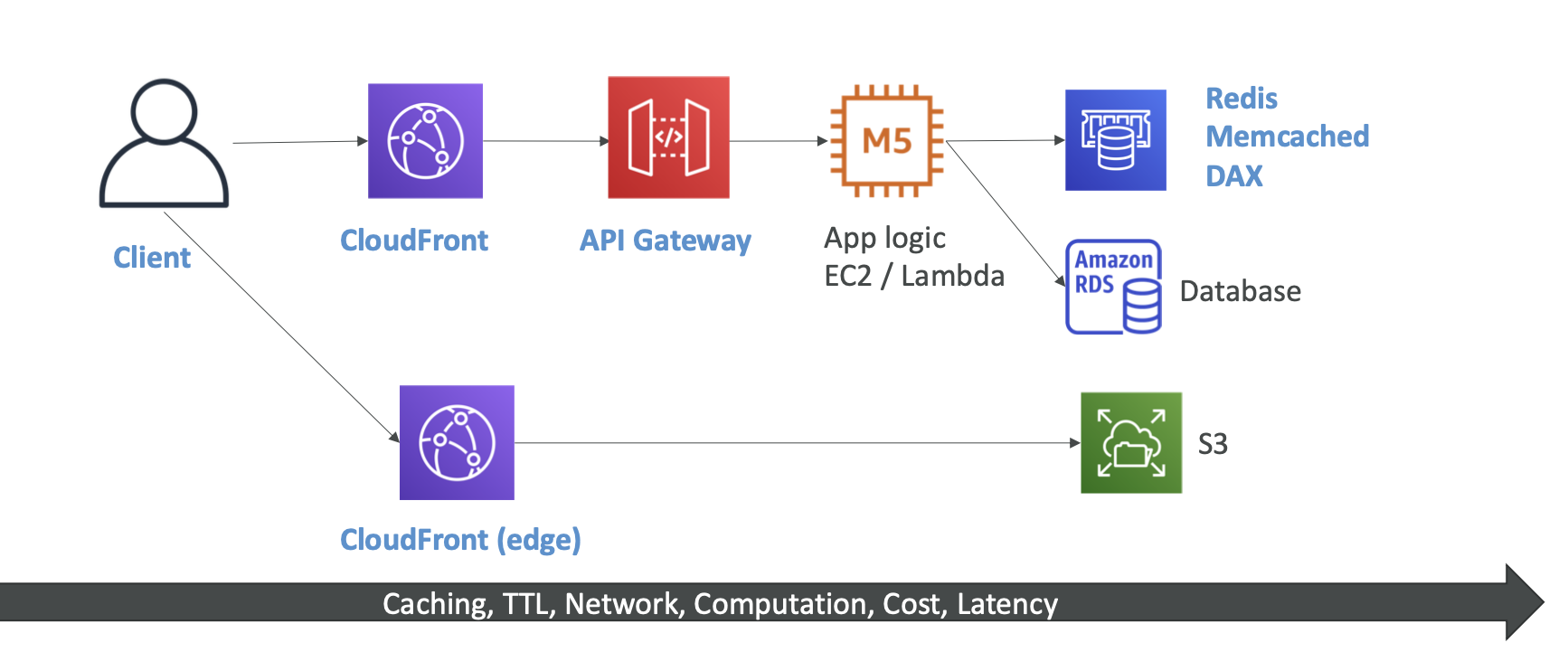
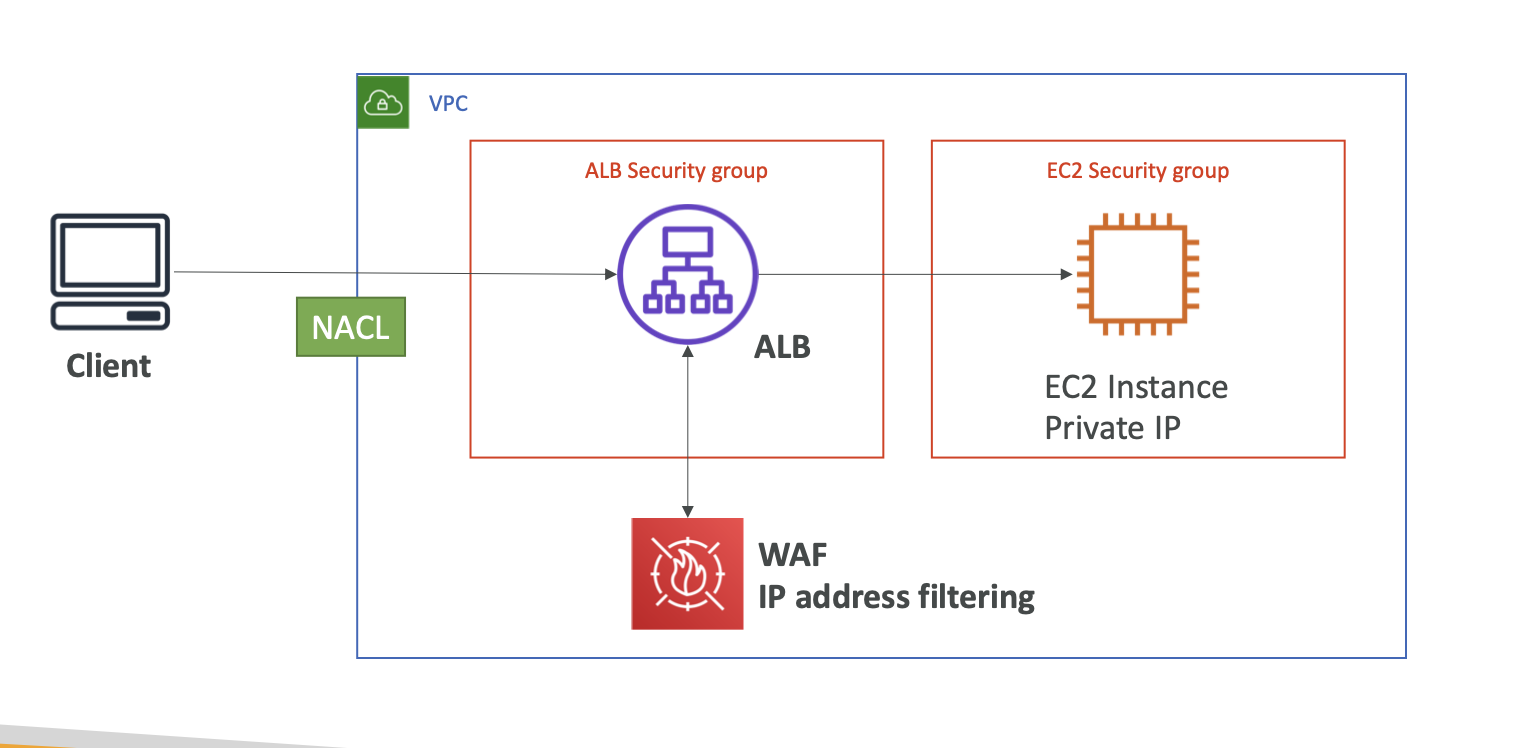
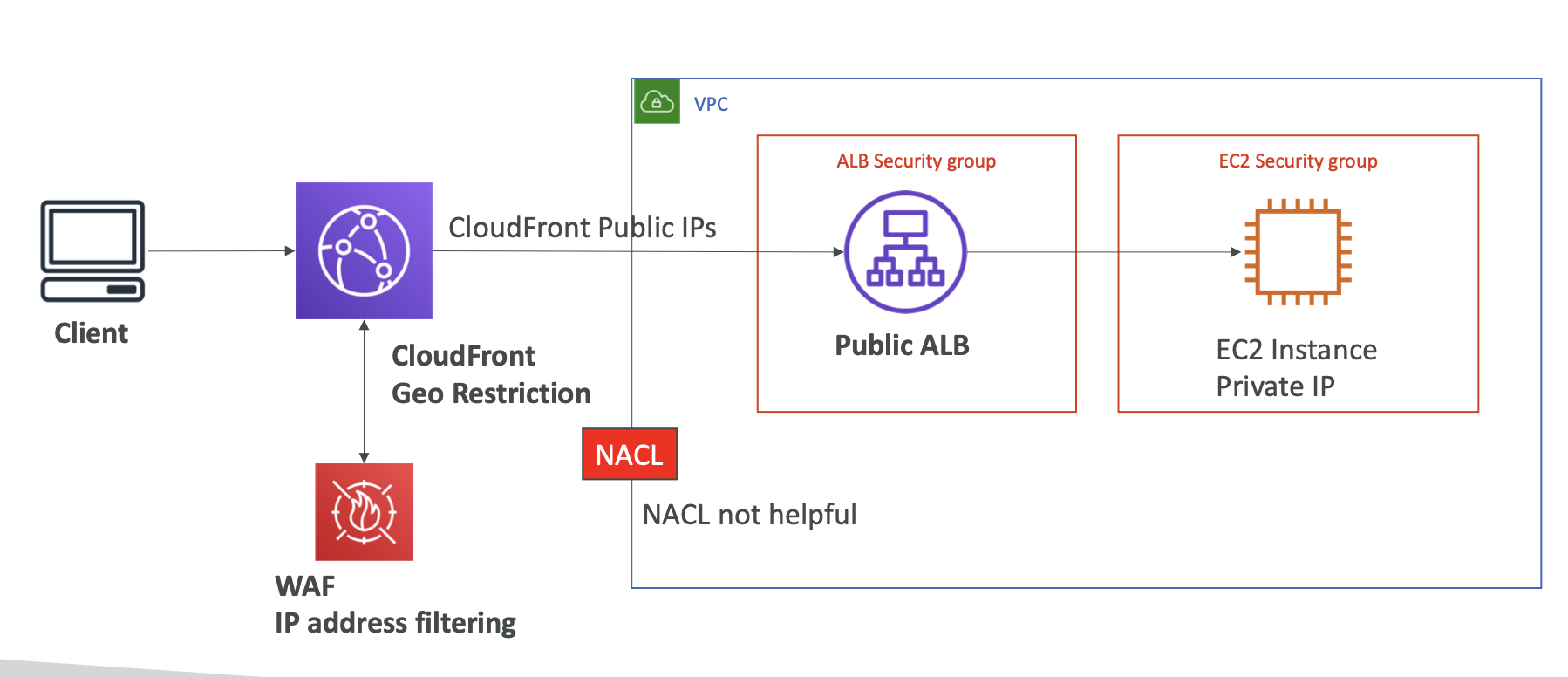
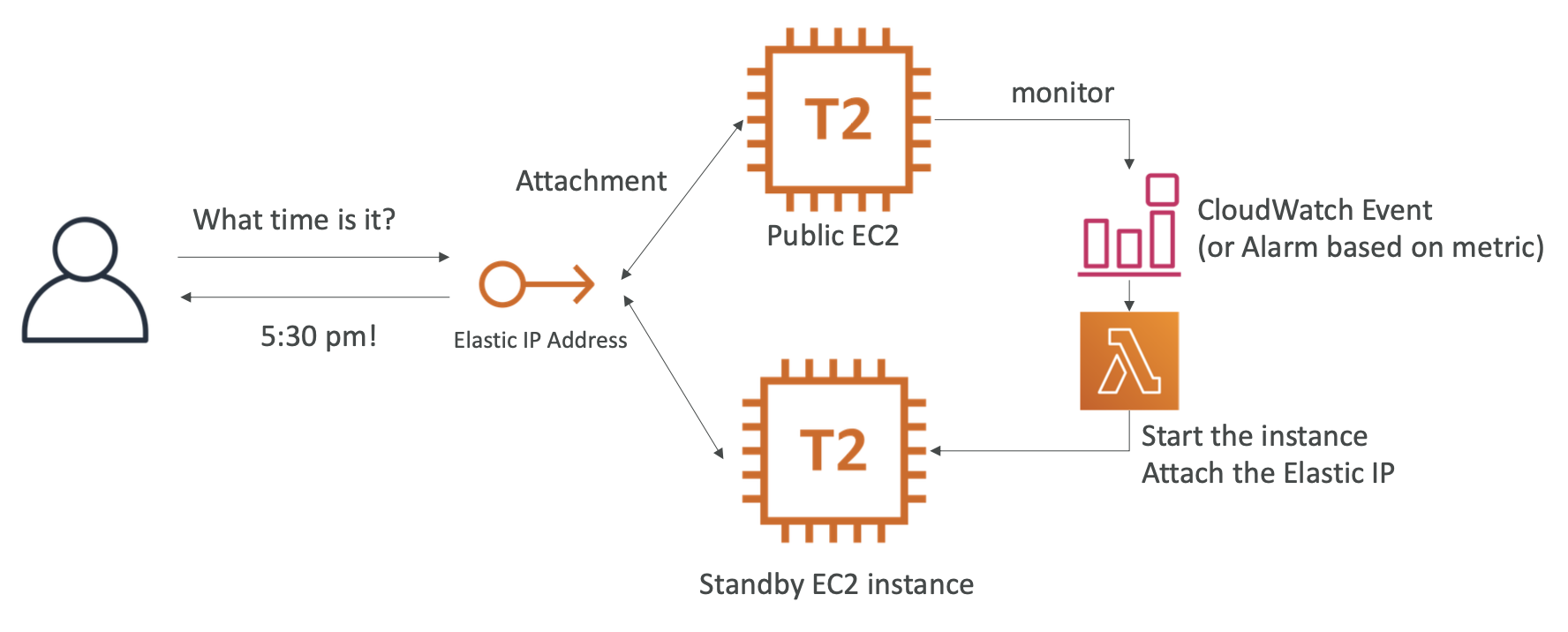
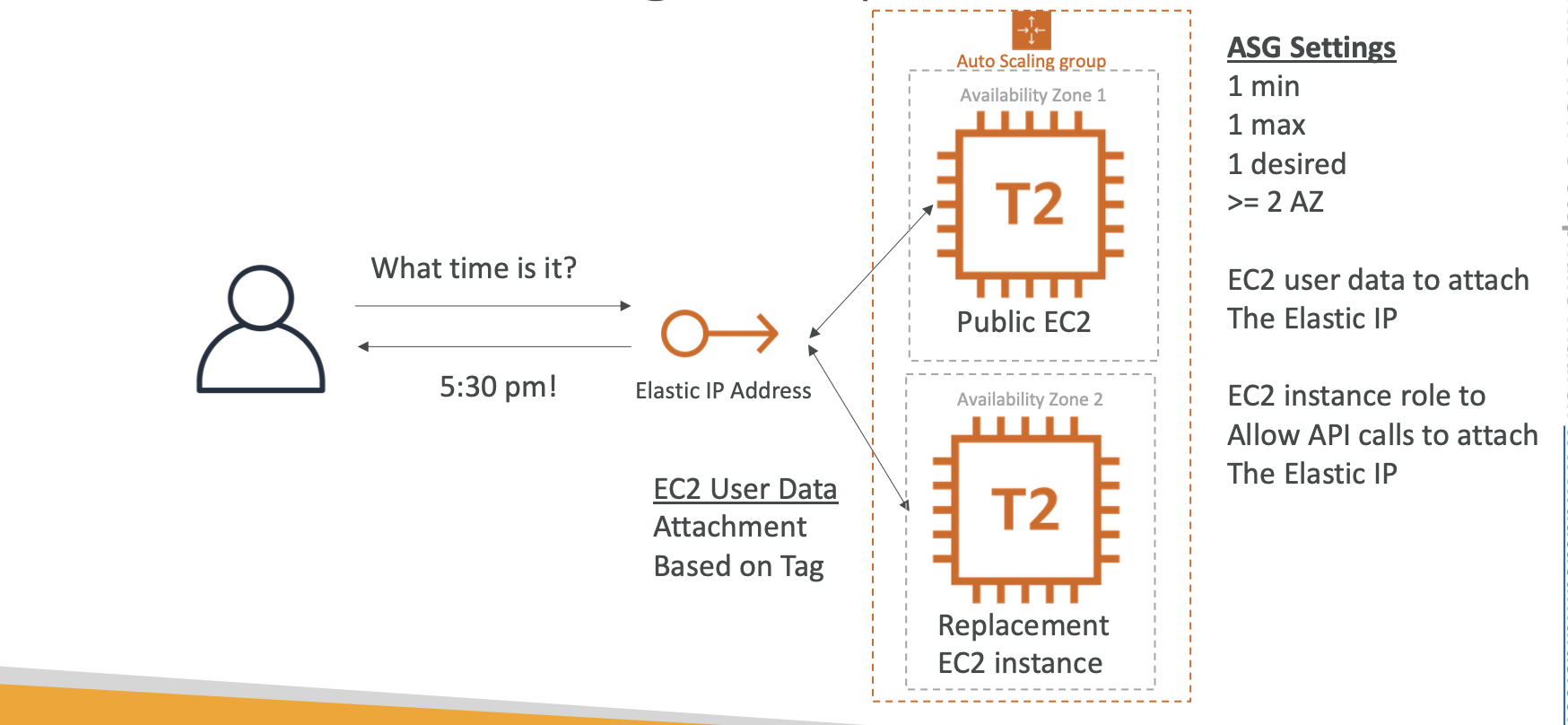
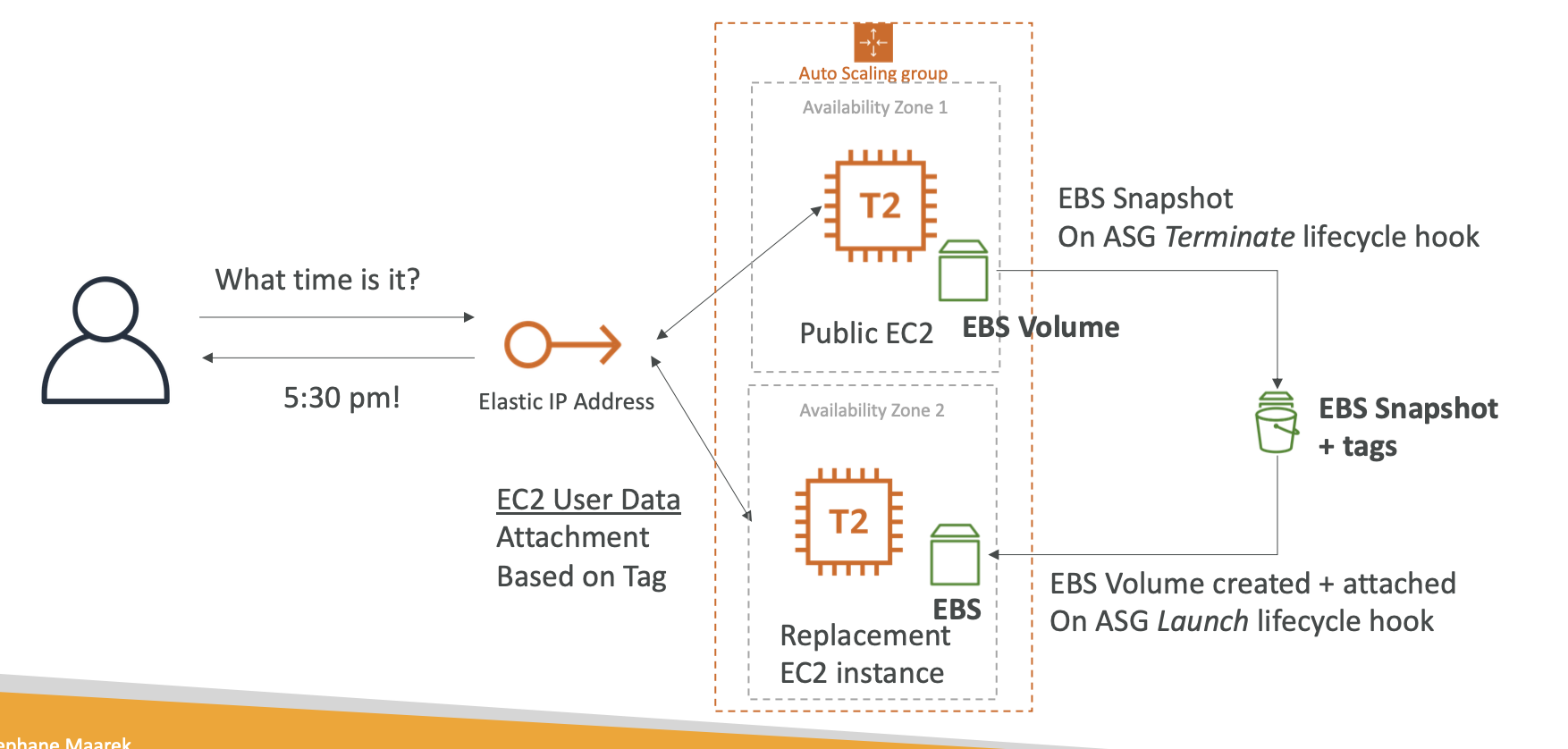
Well Architected Tool
- Operation Excellence
- Includes the ability to run and monitor systems to deliver business value and to continually supporting processes and procedures
- Design Principles
- Perform operations as code
- Annotate documentation - Automate the creation of annotated documentation after every build
- Make frequent, small, reversible changes - So that is case of any failure, you can reverse it
- Refine operations procedures frequently - And ensure that team member are familiar with it
- Anticipate failure
- Learn from all operational failures
- AWS Services
- Prepare
- CloudFormation
- Config
- Operate
- CloudFormation
- Config
- CloudTrail
- CloudWatch
- X-Ray
- Evolve
- CloudFormation
- CodeBuild
- CodeCommit
- CodeDeploy
- CodePipeline
- Prepare
- Security
- Includes the ability to protect information, systems, and assets while delivering business value through risk assessments and mitigation strategies
- Design Principles
- Implement a strong identity foundation - Centralize privilege management and reduce (or even eliminate) reliance on long-term credentials - Principle of least privilege - IAM
- Enable traceability - Integrate logs and metrics with systems to automatcially respond and take action
- Apply security at all layers - Like edge network, VPC, subnet, load balancer, every instance, operating system, and application
- Automate security best practices
- Protect data in transit and at rest - Encryption, tokenization, and access control
- Keep people away from data - Reduce or eliminate the need for direct access or manual processing of data
- Prepare for security events - Run incident response simulations and use tools with automation to increase your speed for deletion, investigation, and recovery
- AWS Services
- Identity and Access Management
- IAM
- STS
- MFA token
- Organizations
- Detective Controls
- Config
- CloudTrail
- CloudWatch
- Infrastructure Protection
- CloudFront
- VPC
- Shield
- WAF
- Inspector
- Data Protection
- KMS
- S3
- ELB
- EBS
- RDS
- Incident Response
- IAM
- CloudFormation
- CloudWatch Events
- Identity and Access Management
- Reliability
- Ability of a system to recover from infrastructure or service disruptions, dynamically acquire computing resources to meet demand, and mitigate disruptions such as misconfigurations or transient network issues
- Design Principles
- Test recovery procedures - Use automation to simulate different failures or to recreate scenarios that led to failures before
- Automatically recover from failure - Anticipate and remediate failures before they occur
- Scale horizontally to increase aggregate system availability - Distribute requests across multiple, smaller resources to ensure that they don’t share a common point of failure
- Stop guessing capability - Maintain the optimal level to satisfy demand without over or under provisioning - Use Auto Scaling
- Manage change in automation - Use automation to make changes to infrasturcture
- AWS Services
- Foundations
- IAM
- VPC
- Service Limits
- AWS Trusted Advisor
- Change Management
- AWS Auto Scaling
- CloudWatch
- CloudTrail
- Config
- Failure Management
- Backups
- CloudFormation
- S3
- S3 Glacier
- Route 53
- Foundations
- Performance Efficiency
- Includes the ability to use computing resources efficiently to meet system requirements, and to maintain that efficiency as demand changes and technologies evolve
- Design Principles
- Democratize advanced technologies - Advance technologies become services and hence you can focus more on product development
- Go global in minutes - Easy deployment in multiple regions
- Use serverless architectures - Avoid burden of managing servers
- Experiment more often - Easy to carry out comparative testing
- Mechanical sympathy - Be aware of all AWS services
- AWS Services
- Selection
- AWS Auto Scaling
- Lambda
- EBS
- S3
- RDS
- Review
- CloudFormation
- AWS News Blog
- Monitoring
- CloudWatch
- Lambda
- Tradeoffs
- RDS
- ElastiCache
- Snowball
- CloudFront
- Selection
- Cost Optimization
- Includes the ability to run systems to deliver business value at the lowest price point
- Design Principles
- Adopt a consumption mode - Pay only for what you want
- Measure overall efficiency - Use CloudWatch
- Stop spending money on data center operations - AWS does the infrastructure part and enables customer to focus on organization projects
- Analyze and attribute expenditure - Accurate identification of system usage and costs, helps measure return on investment (ROI) - Make sure to use tags
- Use managed and application level services to reduce cost of ownership - As managed services at cloud scale, they can offer a lower cost per transaction or service
- AWS Services
- Expenditure Awareness
- AWS Budgets
- AWS Cost and Usage Report
- AWS Cost Explorer
- Reserved Instance Reporting
- Cost-Effective Resources
- Spot Instance
- Reserved Instance
- S3 Glacier
- Matching supply and demand
- AWS Auto Scaling
- Lambda
- Optimizing Over Time
- AWS Trusted Advisor
- AWS Cost and Usage Report
- AWS News Blog
- Expenditure Awareness
Trusted Advisor
- No need to install anything - high level AWS account assessment
- Analyze your AWS accounts and provides recommendation
- Cost Optimization
- Performance
- Security
- Fault Tolerance
- Service Limits
- Full Trusted Advisor - Available for Business & Enterprise support plans
- Ability to set CloudWatch alarms when reaching limits
- It is an online tool that provides you real-time guidance to help you provision your resources following AWS best practices.
Savings Plans
- Savings Plans is a flexible pricing model that provides low prices in exchange for commitment
- Supported services
- EC2
- Fargate
- Lambda
- SageMaker
- Types of Savings Plans
- Compute Savings Plans
- reduce your costs by up to 66%
- automatically apply to EC2 instance usage regardless of instance family, size, AZ, region, OS or tenancy, and also apply to Fargate or Lambda usage
- EC2 Instance Savings Plans
- provides the lowest prices
- savings up to 72%
- EC2 Instance Savings Plans apply to usage regardless of size, OS, or tenancy within the spcified family
- Compute Savings Plans
- Note:
- AWS Reserved Instance is only for EC2
- AWS Spot Instance is only for EC2
- Savings Plans don’t support RDS
SageMaker
- is a fully managed machine learning service. With SageMaker, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment
ParallelCluster
- ParallelCluster is an AWS-supported open source cluster management tool that makes it easy for you to deploy and manage HPC clusters on AWS.
- It is built on the popular open source CfnCluster project is released via the Python Package Index (PyPI).
- ParallelCluster is available at no additional charge, and you only pay for the AWS resources needed to run your applications.
- ParallelCluster supports EFA, which can get OS-bypass capabilities (kernel-bypass networking), which is possible only in specific instance types and limited to a single subnet. Also, you cannot attach an EFA to an instance that is in the running state.
- EFA support is not enabled by default and is not supported in any EC2 instance type.
Certificate Manager
- Certificate Manager can be used to generate SSL certicates to encrypt traffic in transit, but not at rest.
Lake Formation
- AWS Lake Formation is a service that makes it easy to set up a secure data lake in days.
- A data lake enables you to break down data silos and combine different types of analytics to gain insights and guide better business decisions.
Control Tower
- The easiest way to set up and govern a secure multi-account AWS environment
- Control Tower is more suitable to automate a deployment in multi-account environments
Cost Explorer
- Visualize, understand, and manage your AWS costs and usage over time
- In Cost Explorer, you can analyze and explore your bills and service usage in the account.
Server Migration Service (SMS)
- Server Migration is used to migrate on-premises workloads to EC2
Migration Hub
- Migration Hub is used to track the progress of migrations in AWS.
Transfer
- AWS Transfer is a better choice for transferring SFTP data between on-premises & S3
Servcie Catalog
- Service Catalog is used to manage catalogs and cannot share resources with others.
- Allow organizations to create and manage catalogs of IT services that are approved for use on AWS. These IT services can include everything from virtual machine images, servers, software, and databases to complete multi-tier application architectures.
Polly
- Amazon Polly is a cloud service that converts text into lifelike speech
- Managing Lexicons
- Pronunciation lexicons enable you to customize the pronunciation of words. Polly provides API operations that you can use to store lexicons in an AWS region. Those lexicons are then specific to that particular region. You can use one or more of the lexicons from that region when syntheizing the text by using the SynthesizeSpeech operation.
CloudSearch
- With CloudSearch, you can quickly add rich search capabilities to your website or application. You don’t need to become a search expert or worry about hardware provisioning, setup, and maintenance.
X-Ray
- X-Ray collects data, analysis and debug of microservice application.
- X-Ray helps to analyze and debug modern applications. It will also collect the trace about the request from each of the applications. It also records the traces. After recording, it can create a view service map that can be seen to trace data latency and analyze the issues. This can help to find any unusual behavior to identify any root cause.
AWS Batch
- Batch helps you to run batch computing workloads on the AWS Cloud.
- Batch simplifies running batch jobs across multiple AZs within a Region. You can create Batch compute environments within a new or existing VPC. After a compute environment is up and associated with a job queue, you can define job definitions that specify which Docker container images to run your jobs. Container images are stored in and pulled from container registries, which may exist within or outside of your AWS infrastructure.
- Components
- Jobs
- A unit of work (such as a shell script, a Linux executable, or a Docker container image) that you submit to AWS Batch.
- Job Definitions
- A job definition specifies how jobs are to be run. You can supply your job with an IAM role to provide access to other AWS resources. You also specify both memory and CPU requirements. The job definition can also control container properties, environment variables, and mount points for persistent storage.
- Job Queues
- When you submit an AWS Batch job, you submit it to a particular job queue, where the job resides until it’s scheduled onto a compute environment. You associate one or more compute environments with a job queue.
- Jobs
- Batch supports both customized AMI and ECS-optimized AMI
- Job States
- SUMITTED
- A job that has been submitted to the queue, and has not yet been evaluated by the scheduler
- PENDING
- A job that resides in the queue and isn’t yet able to run due to a dependency on another job or resource. After the dependencies are satisfied, the job is moved to RUNNABLE.
- RUNNABLE
- A job that resides in the queue, has no outstanding dependencies, and is therefore ready to be scheduled to a host. Jobs can remain in this state indefinitely when sufficient resources are unavailable.
- STARTING
- These jobs have been scheduled to a host and the relevant container initiation operations are underway. After the container image is pulled and the container is up and running, the job transactions to RUNNING.
- RUNNING
- The job is running as a container job on ECS container instance within a compute environment. If the job associated with a failed attempt has any remaining attempts left in its optional retry strategy configuration, the job is moved to RUNNABLE again.
- SUCCEEDED
- The job has successfully completed with an exit code of 0. The job state for SUCCEEDED jobs is persisted in Batch for at least 24 hours.
- FAILED
- The job has failed all available attempts. The job state for FAILED jobs is persisted in Batch for at least 24 hours.
- SUMITTED
- Job Stuck in RUNNABLE Status
- The AWS logs log drivers isn’t configured on your compute resources
- AWS Batch jobs send their log information to CloudWatch Logs. To enable this, you must configure your compute resources to use the AWS logs log driver.
- Insufficient resources
- If your job definitions specify more CPU or memory resources than your compute resources can allocate, then your jobs is never placed.
- No internet access for compute resources
- Compute resources need access to communicate with ECS service endpoint. This can be through an interface VPC endpoint or through your compute resources having public IP addresses.
- Amazon EC2 instance limit reached
- The number of Amazon EC2 instances that your account can launch in an AWS Region is determined by your EC2 instance limit. Certain instance types have a per-instance-type limit as well.
- The AWS logs log drivers isn’t configured on your compute resources
- Priority
- You can create multiple Job queues with different priority and mapped Compute environments to each Job queue. When Job queues are mapped to the same compute environment, queues with higher priority are evaluated first.
- Job Queue Parameters
- Job queue name
- State
- The state of the job queue. If the job queue state is ENABLED (the default value), it can accept jobs.
- Priority
- The priority of the job queue. Job queues with a higher priority (or a higher integer value for the priority parameter) are evaluated first when associated with same compute environment.
- Priority is determined in descending order.
- All the compute environments must be either EC2 (EC2 or SPOT) or Fargate (FARGATE or FARGATE_SPOT)
- EC2 and Fargate compute environments can’t be mixed
CodePipeline
- To automatically trigger pipeline with changes in the source S3 bucket, CloudWatch Events rule & CloudTrail trail must be applied. When there is a change in the S3 bucket, events are filtered using CloudTrail & then CloudWatch events are used to trigger the start of the pipeline. This default method is faster and periodic checks should be disabled to have events-based triggering of CodePipeline.
- Webhooks are used to trigger pipeline the source is GitHub repository
- Periodic checks are not a faster way to trigger CodePipeline