Hive-based Enterprise Data Warehouse(EDW)

Prerequisite
Establishing a complete Hadoop ecosystem such as using Ambari.
For how to establish a complete Hadoop ecosystem by Ambari, you can check the posts - “Step by Step Tutorial for Ambari Installation” or “Tutorial for Latest Ambari(2.7.1)”.
Installing Hive for enterprise data warehouse (EDW).
Offering visual Hive query tools such as Hue.
Installing NiFi for processing data flow itinerantly.
Technical Architecture
Business Requirements
- Sync order data from external MySQL database into Hive daily
- Compute order amount by orderID daily
- Compute total order amount daily
- Sync total order amount to external MySQL database daily
Preparations
- Creating databases and tables for Hive of Hadoop ecosystem and MySQL of the external database separately.
- Inserting several order data into the external MySQL database for syncing.
Design of a series of NiFi flow
Firstly, we can create a processor group to package overall processors for easy management.
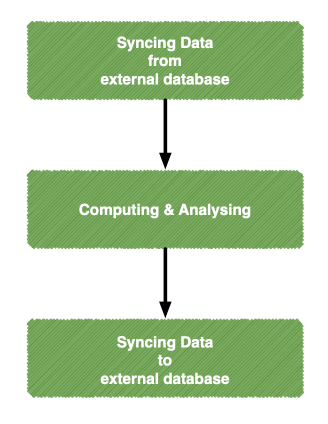
Based on business requirements, I split requirements into main three tasks - syncing data from the external database, computing and analyzing data and syncing data to the external database.
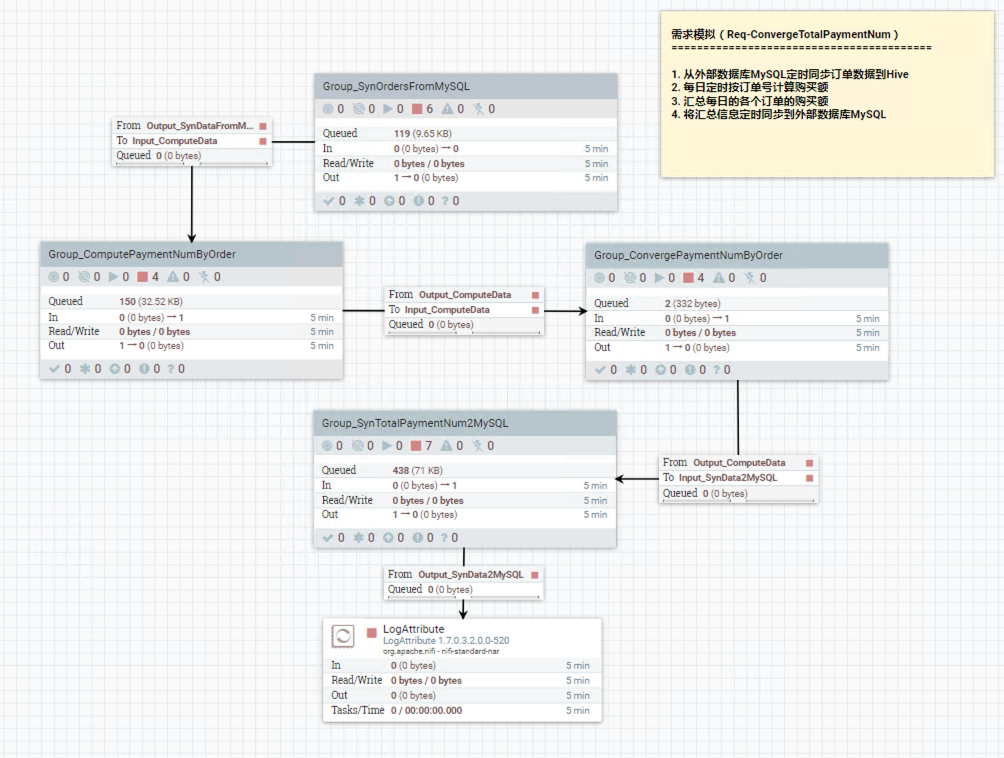
The image above shows the main four NiFi processor groups which contain a series of NiFi processor and I will illustrate all four NiFi processor groups separately.
NiFi Group 1 : Group_SynOrdersFromMySQL
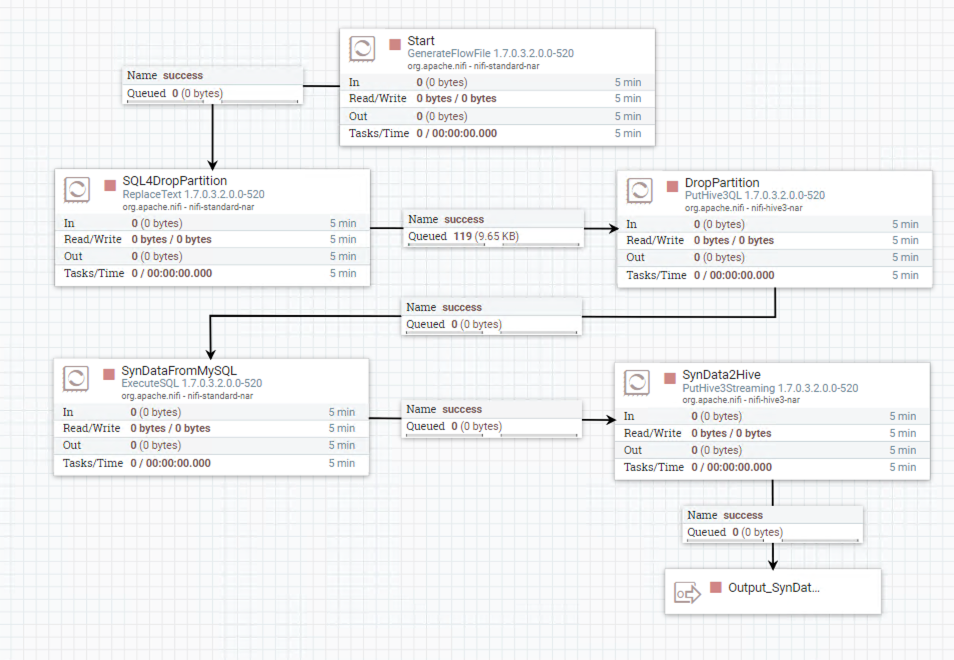
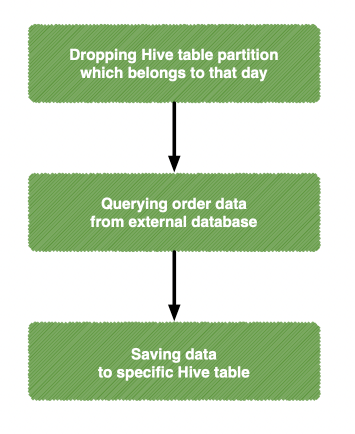
This flow which consists of processor ReplaceText, processor PutHive3QL, processor ExecuteSQL, and processor PutHive3Streaming shows how to grab data from the external MySQL database. Before showing the configuration of each processor, I want to shows a chart to explain the tasks of this flow.
Next, I will state the configuration of each processor in each task step by step.
Dropping Hive table partition which belongs to that day.
This task contains two processors - ReplaceText and PutHive3QL.
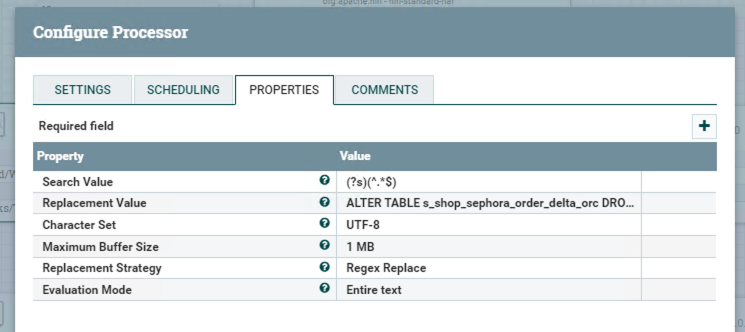
Processor ReplaceText
This processor can replace the identified text segment to an alternative one. But, why we need this processor in task 1? Because the next processor does not provide a SQL input source, so we need a container for loading SQL to the Hive processor.
Adding drop SQL to blank “Replacement Value”.

Drop SQL:
1
ALTER TABLE s_shop_sephora_order_delta_orc DROP IF EXISTS PARTITION(dt='${now():format('yyyyMMdd')}');
Using built-in code ${now():format(‘yyyyMMdd’)} to get current day code.
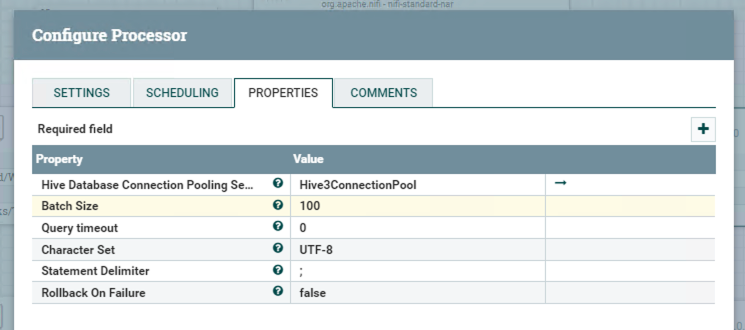
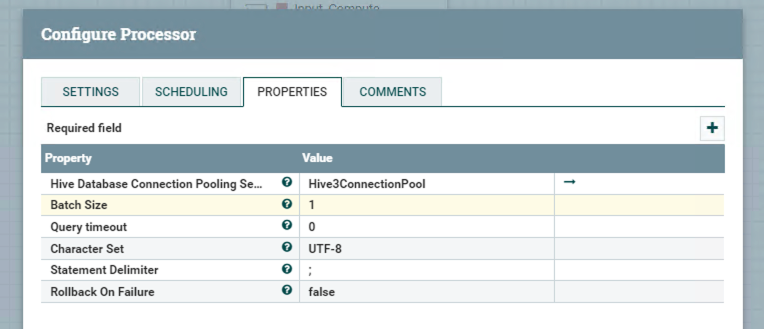
Processor PutHive3QL
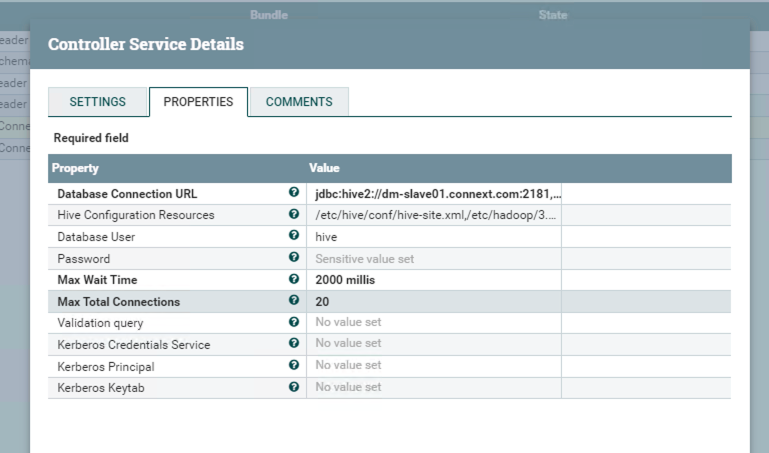
PutHive3QL can connect to Hive and execute SQL generated from the previous processor.
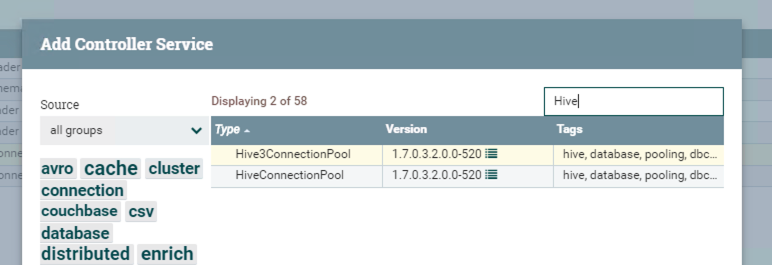
Clicking the right arrow in the pic above to configure the Hive3ConnectionPool.
If you do not have that connection pool, you need to create a new one.
The configuration of this connection pool shows blow.
Querying order data from the external database.
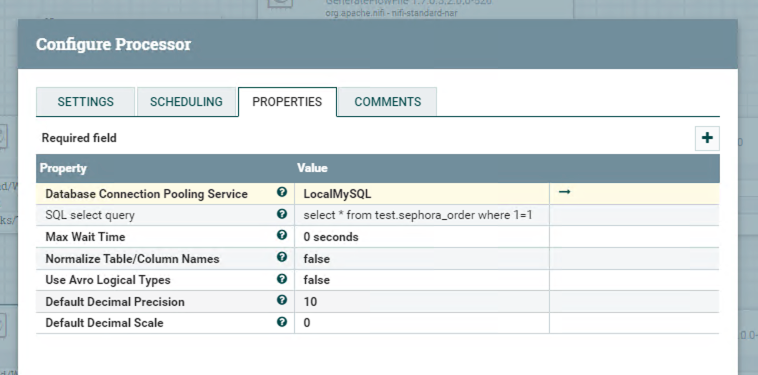
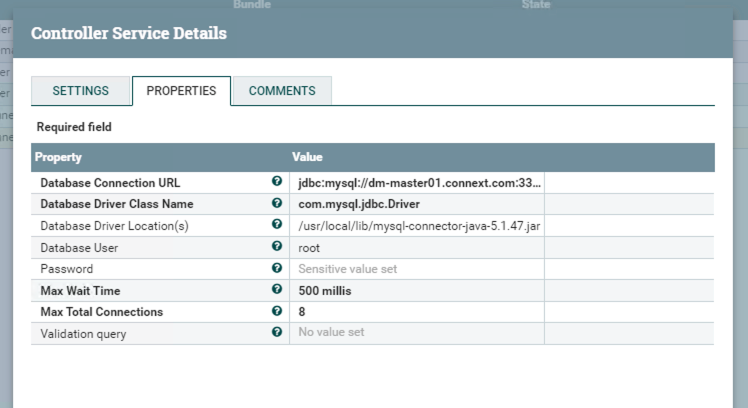
Using processor ExecuteSQL and configuration shows below.
And DBConnectionPool shows below.
Querying SQL:
1
select * from test.sephora_order where 1=1
Saving data to a specific Hive table.
Using processor PutHive3Streaming for inserting dataset to a specific Hive table.
Configuring AvroReader because of the type of the previous dataset.
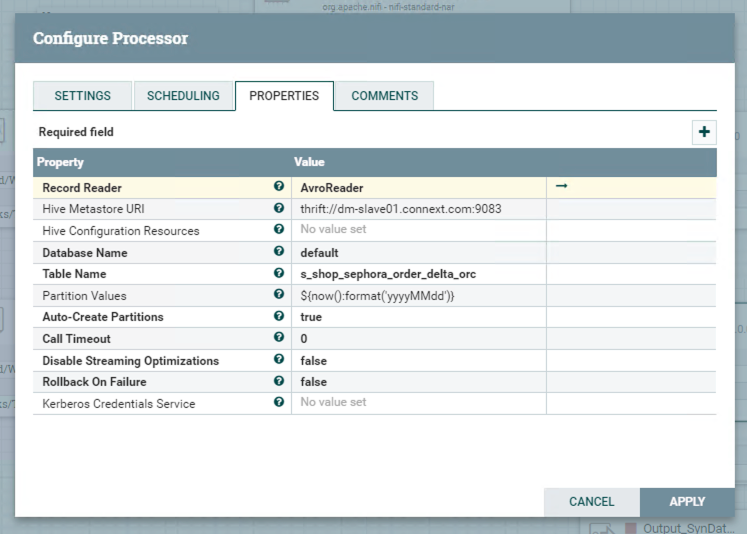
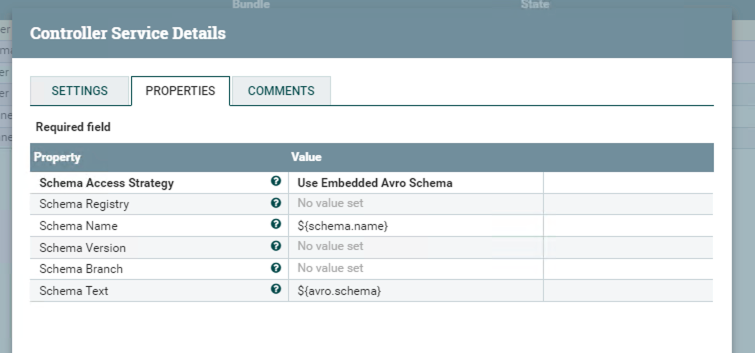
Until now, we can test the whole flow for accuracy.
NiFi Group 2 : Group_ComputePaymentNumberByOrder
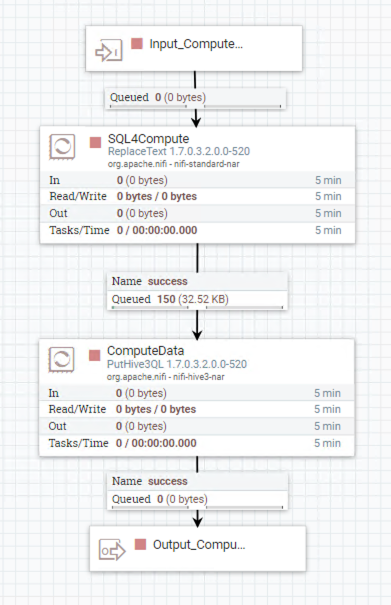
In this flow, we just use the processor to execute Hive SQL for computing data or analyzing data.
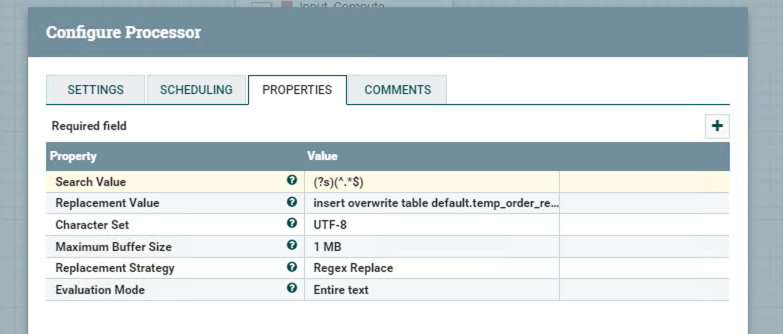
Processor ReplaceText
The same with the previous processor in the last task, this processor just used for storing SQL.
Computing SQL:
1
2insert overwrite table default.temp_order_result_orc partition(dt='${now():format('yyyyMMdd')}')
select order_num,province,city,region,address,(cast(order_amount AS FLOAT) + 1) from default.s_shop_sephora_order_delta_orc where dt='${now():format('yyyyMMdd')}';Processor PutHive3QL
NiFi Group 3 : Group_ConvergePaymentNumByOrder
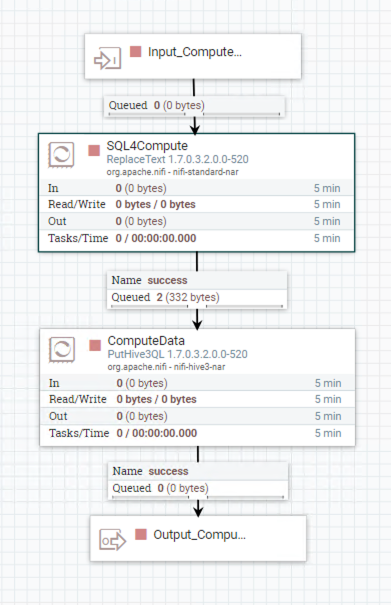
In this step, we need to compute the total order amount.
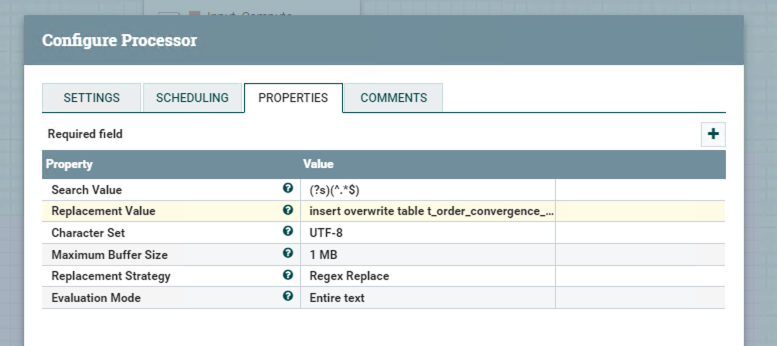
Processor ReplaceText
The Configuration shows below.
Computing SQL:
1
2insert overwrite table t_order_convergence_orc partition(dt='${now():format('yyyyMMdd')}')
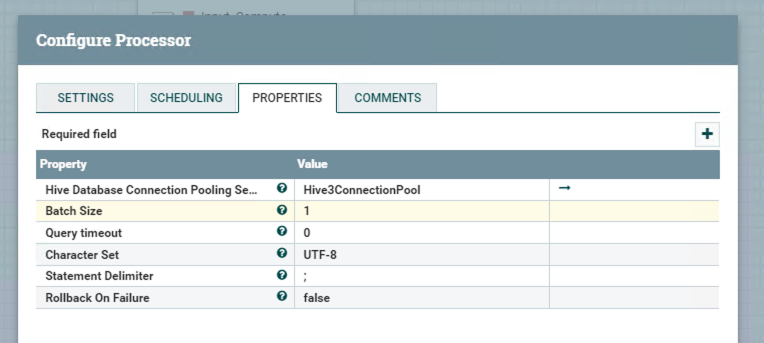
select order_num,sum(total) from temp_order_result_orc where dt='${now():format('yyyyMMdd')}' group by order_num;Processor PutHive3QL
The configuration shows below.
NiFi Group 4 : Group_SynTotalPaymentNum2MySQL
This is the last step for this whole POC and the overview flow chart shows below.
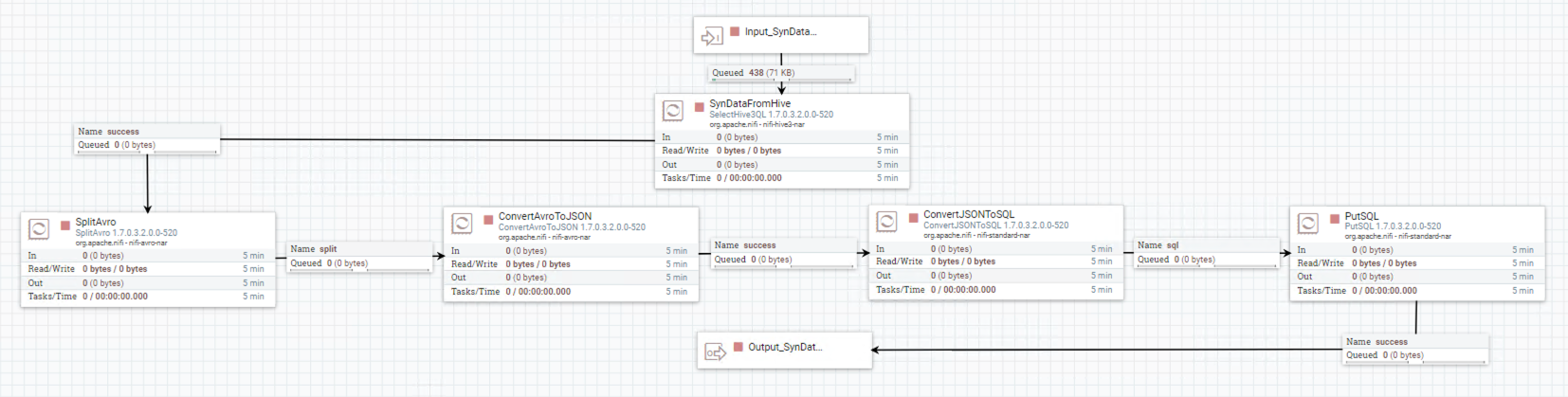
In this step, I split into five processors for querying result data from the Hive table and saving them to the specific external MySQL table. Next, I will state the function and the configuration of each processor respectively.
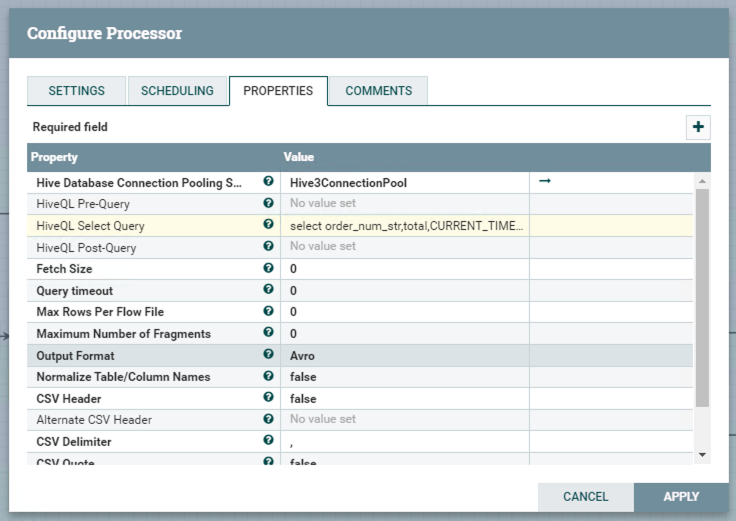
Processor SelectHive3QL
Querying analysis result data from the Hive table and qualifying output format “Avro”.
Since we only have two output formats - Avro and CSV, we can convert Avro to SQL successively.
Querying Data:
1
select order_num_str,total,CURRENT_TIMESTAMP as update_time from default.t_order_convergence_orc where dt = '${now():format('yyyyMMdd')}'
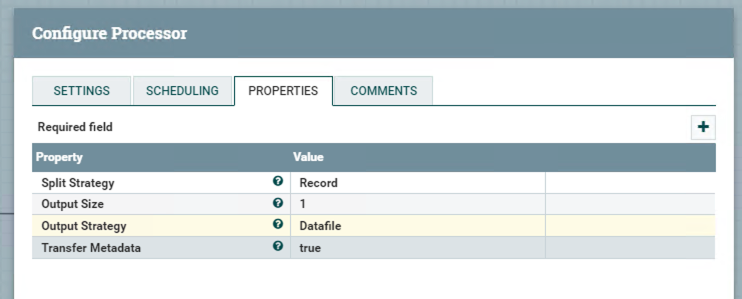
Processor SplitAvro
In this processor, we need to split the Avro dataset because the next processors cannot process the dataset.
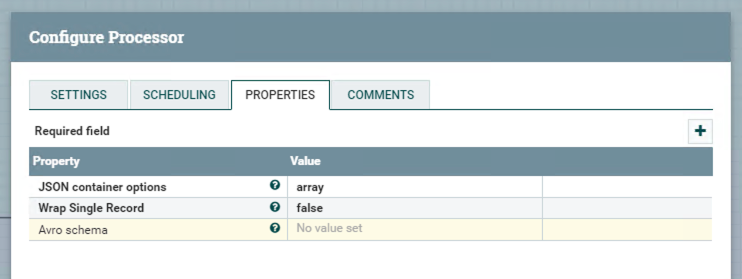
Processor ConvertAvroToJSON
Before converting to SQL, we need to convert to JSON firstly.
Processor ConvertJSONToSQL
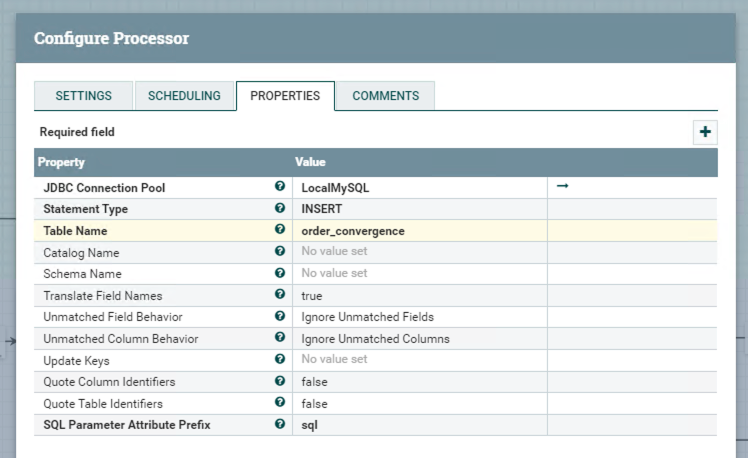
Specifying table name of the external MySQL database in this processor.
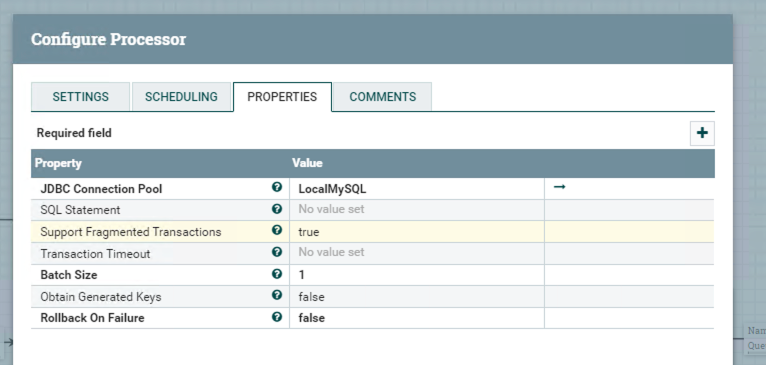
Processor PutSQL

Summary
To sum up, we can use NiFi as a scheduling tool to process data itinerantly since NiFi provides abundant processors for distinct processing.
For now, we can run and test this whole processor group.